
Der Benchmark TravelPlanner soll testen, ob ein Sprachmodell eine Reise planen kann. In den ersten Tests versagen alle Modelle - auch GPT-4.
Forschende der Fudan University, der Ohio State University, der Pennsylvania State University und von Meta AI haben einen neuen Benchmark entwickelt, der die Fähigkeit von KI-gesteuerten Sprachagenten testet, komplexe Reisepläne unter Berücksichtigung zahlreicher Einschränkungen zu erstellen.
Die Fähigkeit zur Planung gilt als ein wichtiges Merkmal menschlicher Intelligenz, das auch die Nutzung verschiedener Werkzeuge zur Informationsbeschaffung und Entscheidungsfindung umfasst. TravelPlanner nimmt die Reiseplanung als Beispiel und zeigt, dass trotz der Fortschritte bei großen Sprachmodellen GPT-4 und andere Modelle erhebliche Schwierigkeiten haben, solche realitätsnahen Planungen durchzuführen.
TravelPlanner testet Planung inklusive Flugsuche
In TravelPlanner müssen die Modelle detaillierte Reisepläne auf der Grundlage spezifischer Benutzeranfragen erstellen. Dabei müssen sie Benutzerbedürfnisse wie Budget und Zimmertyp erhalten und auch implizite "Common Sense"-Beschränkungen berücksichtigen, etwa bei der Auswahl verschiedener Restaurants oder Sehenswürdigkeiten während der Reise.
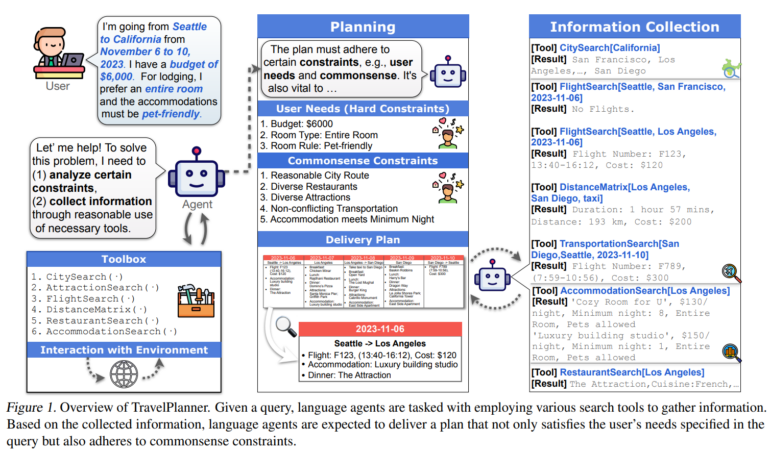
Die Herausforderungen für die Modelle sind dabei komplex: Sie müssen langfristige und voneinander abhängige Entscheidungen treffen, explizite und implizite Einschränkungen berücksichtigen und proaktiv Informationen sammeln und auswerten.
Das Team testete verschiedene große Sprachmodelle wie GPT-3.5-Turbo, GPT-4-Turbo und Gemini Pro sowie die Open-Source-Modelle Mistral-7B-32K und Mixtral-8x7B-MoE.
GPT-4 scheitert am neuen Benchmark
Die Ergebnisse zeigen, dass selbst das fortschrittlichste Modell, GPT-4-Turbo, nur eine Erfolgsquote von 0,6 % erreichte. Andere Modelle konnten keine einzige Aufgabe erfolgreich lösen. Die Ergebnisse zeigen deutlich, dass aktuelle KI-Modelle allein nicht in der Lage sind, menschliches Niveau zu erreichen, wenn es um komplexe, mehrschichtige Planung geht.

Die Modelle müssten dafür besser in der Lage sein, komplexe Anforderungen zu verstehen und zu integrieren, so das Team, externe Informationen effizienter sammeln und Werkzeuge besser nutzen. Die Forscher vermuten zudem, dass die Leistung über erweiterte Gedächtnisfunktionen verbessert werden könnte. Darüber hinaus sei die Entwicklung fortgeschrittener Planungsstrategien und das Training mit realitätsnahen Szenarien wichtig, ergänzt durch interaktives Lernen, um kontinuierliche Verbesserungen zu ermöglichen.
TravelPlanner stellt damit eine wichtige Herausforderung für die Entwicklung zukünftiger KI-Systeme dar: Ein KI-System, das den Benchmark knackt, würde die KI-Forschung ein Stück näher an menschliche Planungsfähigkeiten bringen.




