KI-Modell "Emo" lässt jedes Bild täuschend echt sprechen oder singen

Ein Bild, eine Tonspur - fertig ist der lippensynchrone Deepfake, der von einem echten Video kaum zu unterscheiden ist. Noch ist das KI-Modell "EMO" nicht verfügbar, aber die Folgen sind absehbar.
Forscherinnen und Forscher der Alibaba Group haben ein neuartiges Framework namens EMO entwickelt, das die Realitätsnähe und Ausdruckskraft bei der Erstellung sprechender Videoköpfe verbessert. EMO verwendet einen direkten Audio-zu-Video-Syntheseansatz, der auf stabiler Diffusion basiert und die Notwendigkeit von 3D-Zwischenmodellen oder Gesichtsmarkierungen vermeidet. Die Methode gewährleistet nahtlose Übergänge zwischen Frames und eine konsistente Charakterdarstellung im Video.
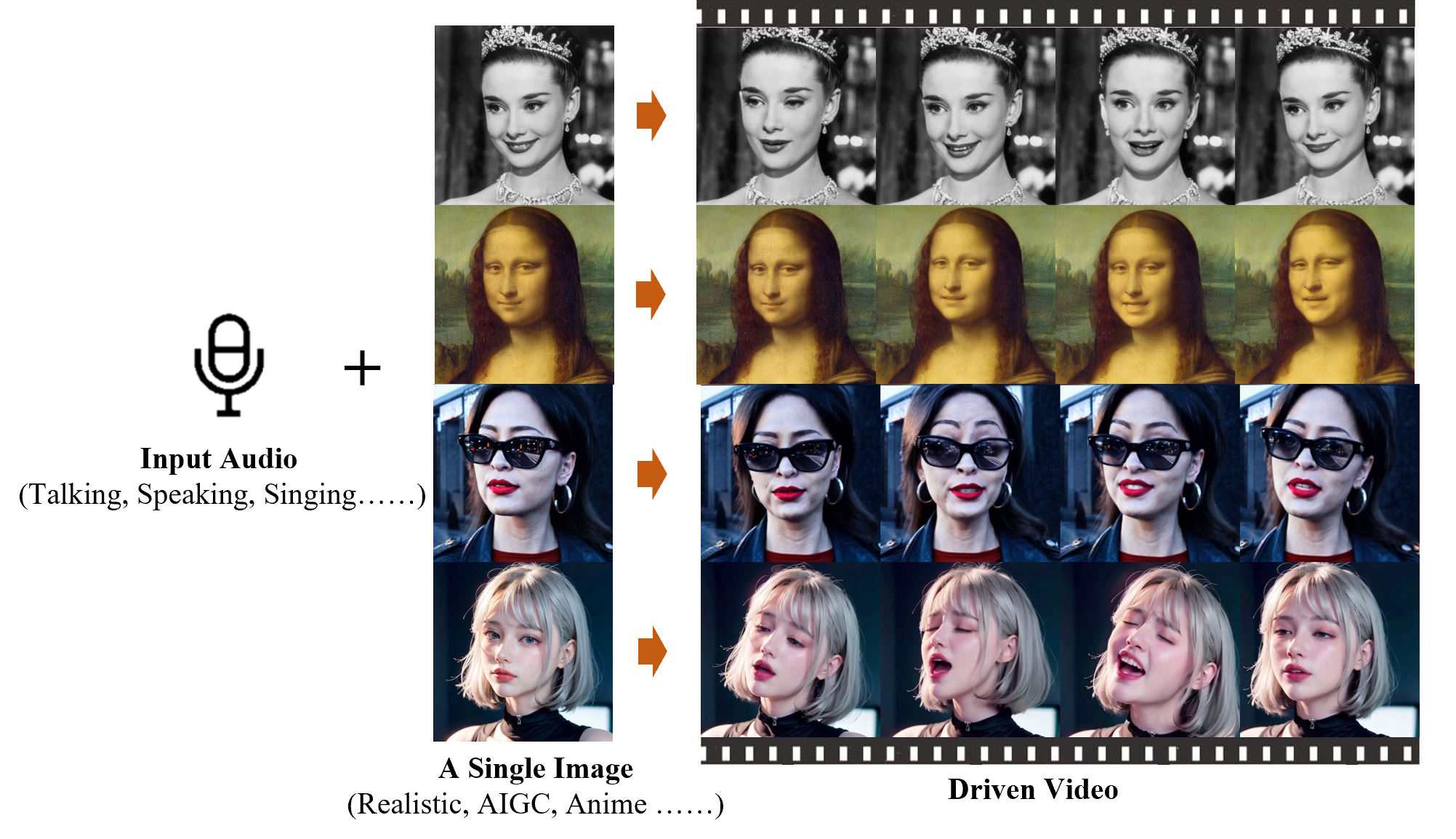
Bemerkenswert ist, dass EMO sowohl sprechende als auch singende Videos in verschiedenen Stilen - von Cartoon über Anime bis zu echten Kameraaufnahmen - und in verschiedenen Sprachen erzeugen kann und dabei bestehende Methoden deutlich übertrifft. Ob Audrey Hepburn, die Mona Lisa oder sogar die japanische Dame aus einem bekannten Sora-Demo-Video - bei allen genügt ein einziges Bild und eine Tonspur, um Lippen und Gesichtsmuskeln in Bewegung zu setzen.
Video: Tian et al.
Video: Tian et al.
Video: Tian et al.
Eine der größten Herausforderungen für die Forscher war die Instabilität der vom Modell erzeugten Videos, die sich häufig in Form von Gesichtsverzerrungen oder Zittern zwischen den Videobildern äußerte. Um dieses Problem zu lösen, integrierten sie Kontrollmechanismen wie einen Geschwindigkeitsregler und einen Gesichtsbereichregler. Diese Regler fungieren als Hyperparameter und dienen als subtile Steuersignale, die die Vielfalt und Ausdrucksstärke der letztlich generierten Videos nicht beeinträchtigen.

Individueller Trainingsdatensatz mit 250 Stunden Material
EMO wurde auf einem speziell erstellten Audio-Video-Datensatz trainiert, der mehr als 250 Stunden Filmmaterial und mehr als 150 Millionen Bilder umfasste. Dieser umfangreiche Datensatz deckt ein breites Spektrum an Inhalten ab, darunter Reden, Film- und Fernsehclips sowie Sprachaufnahmen in mehreren Sprachen. Woher die Daten genau stammen, verraten die Wissenschaftler:innen in ihrem Paper nicht.
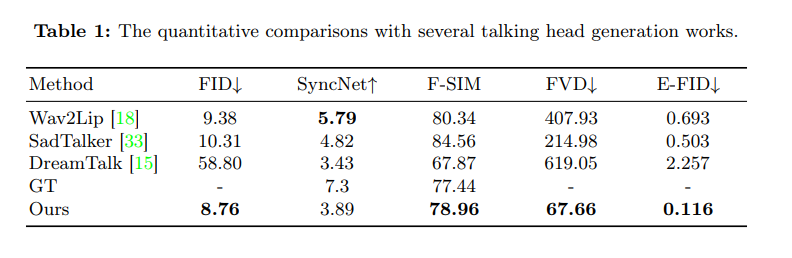
In umfangreichen Experimenten und Vergleichen mit dem Human Dialogue Talking Face (HDTF) Datensatz übertraf der EMO-Ansatz die derzeit besten konkurrierenden Methoden in mehreren Metriken wie Fréchet Inception Distance (FID), SyncNet, F-SIM und FVD.
Obwohl EMO einen bedeutenden Fortschritt im Bereich der Videogenerierung darstellt, räumen die Forscher einige Einschränkungen ein. Die Methode ist zeitaufwendiger als andere, die nicht auf Diffusionsmodellen basieren. Außerdem kann das Modell ohne explizite Steuersignale, die die Bewegung der Figur lenken, unbeabsichtigt andere Körperteile erzeugen. Zukünftige Arbeiten werden sich wahrscheinlich mit diesen Herausforderungen befassen.
Ob und wenn ja, wo die Alibaba Group solche Forschungen überhaupt anwenden und den Nutzer:innen zur Verfügung stellen will, ist nicht klar. Einerseits bieten solche Technologien ein enormes Missbrauchspotenzial, wenn damit in kürzester Zeit realitätsnahe Deepfake-Videos erstellt und in Kombination mit einem der zahlreichen Audio-Deepfake-Tools etwa Politiker:innen alle möglichen Worte in den Mund gelegt werden können. Gerade im wichtigen US-Wahljahr 2024 blicken Expert:innen mit großer Sorge auf die Risiken von Deepfakes.
Andererseits sind diese Entwicklungen für die Unterhaltung spannend und könnten in Social-Media-Anwendungen wie TikTok oder in der Filmindustrie für eine noch realistischere Synchronisation eingesetzt werden.
In jüngster Zeit hat sich eine Reihe von Unternehmen mit KI-Lippensynchronisation befasst, darunter auch das KI-Start-up Pika Labs. Der Anbieter eines vielversprechenden KI-Videomodells hat die Lip-Sync-Funktion erst in den letzten Wochen in sein Produkt integriert.
Ein weiterer prominenter Vertreter in diesem Bereich ist HeyGen, das bereits im vergangenen Jahr mit einer überzeugenden Kombination aus Stimmklon und Lip-Syncing auf sich aufmerksam gemacht hat.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.