Nvidia will mit Lyra 2.0 Robotertraining in Simulationen skalieren
Nvidia-Forscher stellen Lyra 2.0 vor, ein System, das aus einem einzelnen Foto große, zusammenhängende 3D-Umgebungen generiert. Die erzeugten Szenen lassen sich in Echtzeit erkunden und direkt in Robotersimulationen einsetzen.
Um rechtliche Probleme zu vermeiden, hat Byteplus mehrere Schutzmaßnahmen eingebaut: Realistische menschliche Gesichter dürfen nicht als Vorlage verwendet werden. Filter sollen die Generierung urheberrechtlich geschützter Inhalte verhindern. Zudem setzt Byteplus den C2PA-Standard ein, mit dem KI-generierte Inhalte als solche erkennbar gemacht werden. Geprüfte Kunden können über eine Bibliothek mit über 10.000 virtuellen Personen arbeiten oder eine ausdrückliche Genehmigung realer Personen einholen.
Indiens IT-Absolventen sind auf die KI-Revolution kaum vorbereitet
Ein Bloomberg-Bericht zeigt, wie agentenbasierte KI Indiens milliardenschwere IT-Branche erschüttert. Unternehmen wie Infosys müssen Neueinstellungen wochenlang nachschulen, weil die Universitäten des Landes an der Realität vorbei ausbilden.
Google hat eine native Gemini-App für den Mac veröffentlicht. Es ist die erste Desktop-Version des KI-Assistenten neben den bestehenden Smartphone-Apps. Die App lässt sich per Tastenkombination (Option + Leertaste) jederzeit aufrufen, ohne das aktuelle Programm verlassen zu müssen. Nutzer können ihren Bildschirminhalt mit Gemini teilen und etwa komplexe Diagramme zusammenfassen lassen. Auch lokale Dateien, Google Drive, Photos und NotebookLM können eingebunden werden.
Zu den verfügbaren Werkzeugen gehören Bild-, Video- und Musikerstellung sowie Deep Research und Canvas. Die App ist kostenlos, setzt macOS 15 oder höher voraus und ist weltweit unter gemini.google/mac verfügbar. Google nennt die Veröffentlichung einen ersten Schritt und kündigt weitere Funktionen für die kommenden Monate an.
Apple schickt einen Teil seiner Siri-Entwickler zurück auf die Schulbank. Weniger als 200 Programmierer sollen in einem mehrwöchigen Bootcamp lernen, wie sie KI-Tools wie Anthropics Claude Code oder OpenAIs Codex beim Programmieren einsetzen, berichtet The Information.
Der Grund: Das Siri-Team gelte bei Apple intern seit Jahren als träge und hat den Anschluss an moderne KI-Entwicklungen wie ChatGPT verpasst. Der Zeitpunkt ist brisant, denn schon im Juni will Apple auf der Entwicklerkonferenz WWDC eine komplett überarbeitete Siri vorstellen. Die neue Version soll auf Googles Gemini-Modell basieren und deutlich gesprächsfähiger sein.
Nach dem Bootcamp bleiben rund 60 Leute im Kern-Entwicklungsteam, weitere 60 sollen Siris Leistung und Sicherheit überwachen. Apple hatte das Siri-Team bereits Anfang 2025 umgebaut und Software-Chef Craig Federighi unterstellt. Der frühere KI-Chef John Giannandrea verlässt Apple diese Woche endgültig.
Adobe stellt den Firefly AI Assistant vor, einen neuen KI-Assistenten, der komplexe kreative Arbeitsabläufe über eine einzige Chat-Oberfläche steuert. Der Assistent verbindet Adobes Apps wie Photoshop, Illustrator, Premiere und Lightroom. Nutzer beschreiben in eigenen Worten, was sie erstellen wollen, und der Assistent führt die nötigen Schritte automatisch aus. Nutzer können jederzeit eingreifen.
Sogenannte "Creative Skills" ermöglichen es, mehrstufige Abläufe mit einem einzigen Befehl zu starten, etwa die Anpassung eines Bildes für verschiedene Social-Media-Plattformen. Adobe plant zudem die Anbindung an Chat-Plattformen wie Anthropics Claude. Die öffentliche Beta des AI Assistant soll in den kommenden Wochen starten. Er basiert auf dem Vorprojekt "Project Moonlight", das auf der Adobe MAX vorgestellt wurde.
Zusätzlich erweitert Adobe Firefly um KI-Video- und Bildbearbeitung mit Audio-Optimierung, erweiterten Farbkontrollen und Bildanpassungen. Die Zahl der verfügbaren KI-Modelle wächst auf mehr als 30, neu dabei ist Kling 3.0.
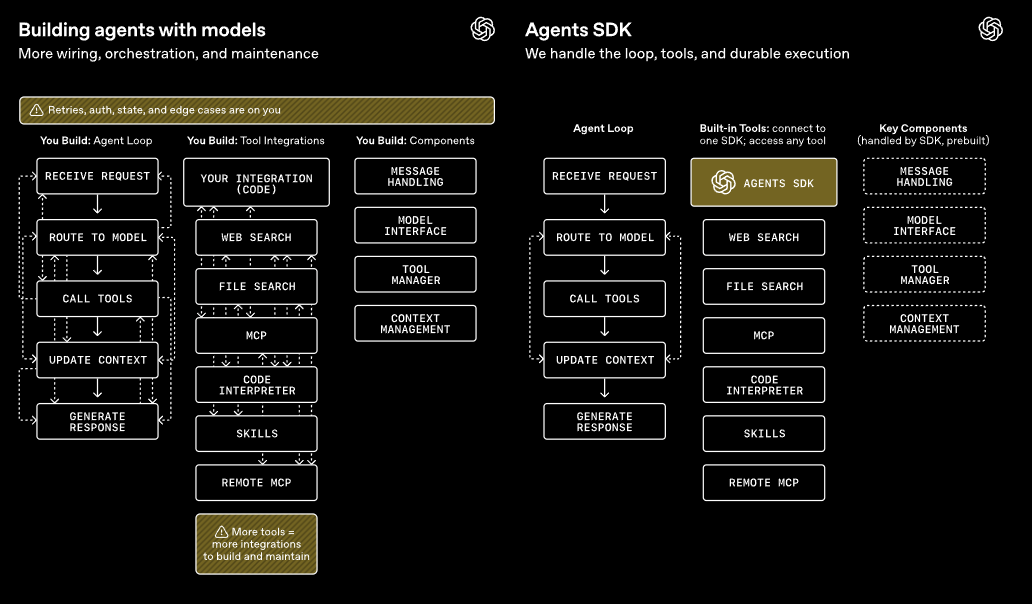
OpenAI hat sein Agents-SDK umfassend aktualisiert. Das Software-Entwicklungskit hilft Programmierern, KI-Agenten zu bauen, die Dateien prüfen, Befehle ausführen, Code bearbeiten und längere Aufgaben in geschützten Umgebungen erledigen können. Es bündelt gängige Bausteine für Agenten-Systeme: Werkzeugnutzung über das Model Context Protocol (MCP), Code-Ausführung über ein Shell-Tool, Dateibearbeitung über ein Apply-Patch-Tool und eigene Anweisungen über AGENTS.md-Dateien. Eine Manifest-Funktion beschreibt den Arbeitsbereich und unterstützt neben lokalen Dateien auch Cloud-Speicher wie AWS S3, Google Cloud Storage und Azure Blob Storage.
Das Diagramm zeigt, wie das Agents-SDK Nutzereingaben, KI-Modelle und Werkzeuge verbindet, um KI-Agenten zu bauen. | Bild: OpenAI
Neu ist eine native Sandbox-Unterstützung: Agenten arbeiten in abgeschotteten Bereichen mit eigenen Dateien, Werkzeugen und Abhängigkeiten. Unterstützt werden Anbieter wie Cloudflare, Vercel, E2B, Modal und weitere. Entwickler können auch eigene Sandboxes einbinden. Die Trennung von Steuerungslogik und Rechenumgebung soll Sicherheit, Stabilität und Skalierbarkeit verbessern. Bei einem Ausfall kann der Agent seinen Zustand in einem neuen Container wiederherstellen. Die neuen Funktionen sind in Python verfügbar, TypeScript soll folgen. Es gelten die normalen API-Preise von OpenAI.
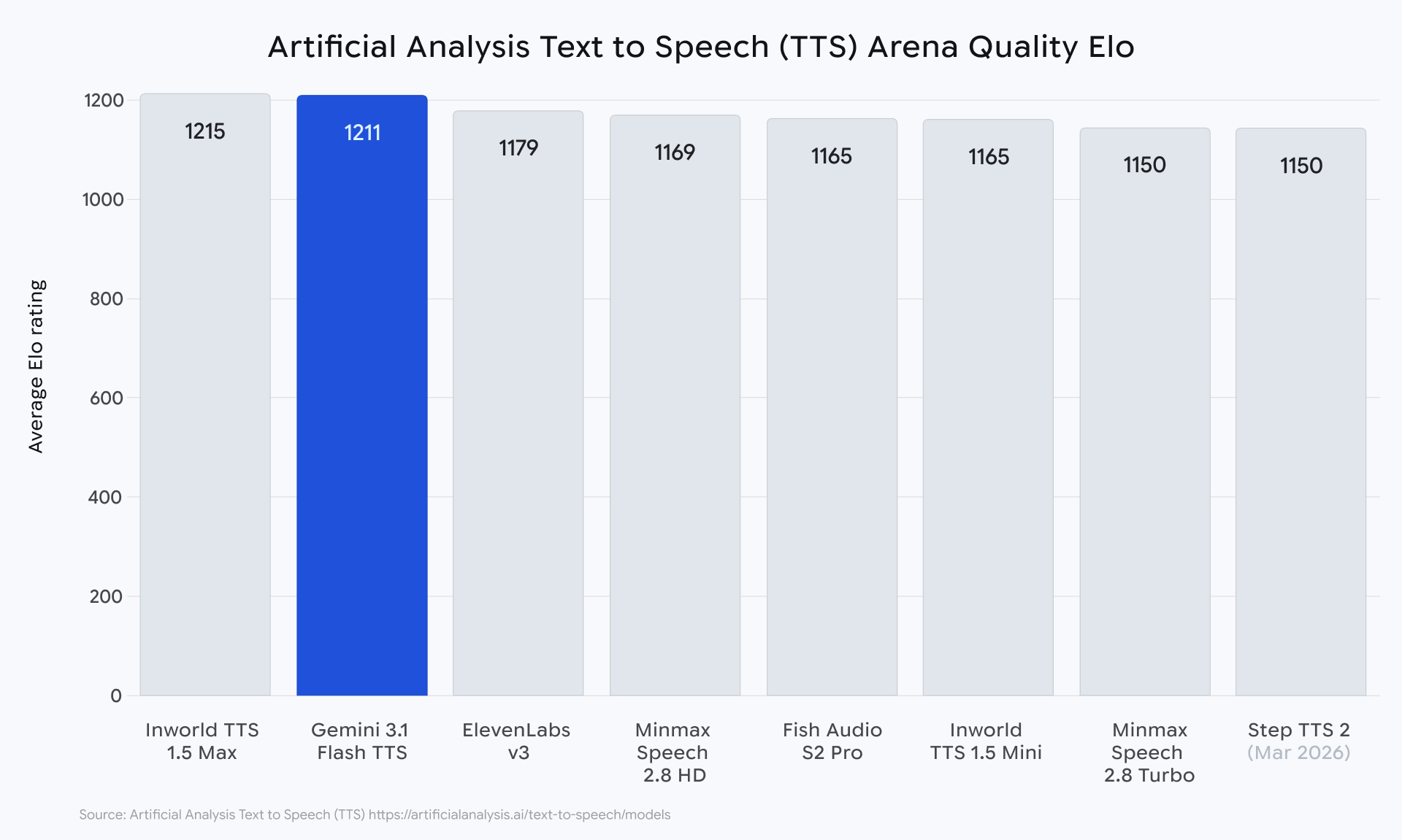
Google rollt sein neues Text-to-Speech-Modell basierend auf Gemini 3.1 Flash aus. Es bietet laut Google die bisher natürlichste und ausdrucksstärkste Sprachausgabe des Unternehmens. Neu sind sogenannte Audio-Tags: Entwickler können per Textbefehle Stil, Tempo, Tonfall und Akzent der Sprachausgabe steuern. Das Modell unterstützt mehr als 70 Sprachen und ermöglicht Dialoge mit mehreren Sprechern.
Auf der Rangliste von Artificial Analysis erreicht das Modell einen Elo-Wert von 1.211 und wird dort als besonders gutes Verhältnis von Qualität und Preis eingestuft. Bei der Qualität insgesamt liegt es vor Elevenlabs v3 und knapp hinter Inworld 1.5 Max.
Bild: Google
Gemini 3.1 Flash TTS bietet eine kostenlose Stufe, bei der Google die Daten zur Produktverbesserung nutzen darf. In der kostenpflichtigen Stufe kostet die Texteingabe 1,00 Dollar pro Million Token, die Audioausgabe 20,00 Dollar pro Million Token. Im Batch-Modus halbieren sich die Preise auf 0,50 Dollar (Texteingabe) und 10,00 Dollar (Audioausgabe). Bei der bezahlten Stufe werden die Daten nicht zur Produktverbesserung verwendet.
Gemini 3.1 Flash TTS ist ab sofort als Vorschau über die Gemini-API, Vertex AI für Unternehmen und Google Vids für Workspace-Nutzer verfügbar. Kostenlos testen kann man es in Googles AI Studio. Alle erzeugten Audiodateien werden mit Googles SynthID-Wasserzeichen versehen, um KI-generierte Inhalte erkennbar zu machen.
Anthropic bereitet Opus 4.7 und KI-Design-Tool vor, VCs bieten bis zu 800 Milliarden Dollar
Anthropic plant die Veröffentlichung eines neuen Modells und eines Design-Tools, das Adobe und Figma Konkurrenz machen soll. Gleichzeitig überbieten sich Risikokapitalgeber mit Bewertungsangeboten.