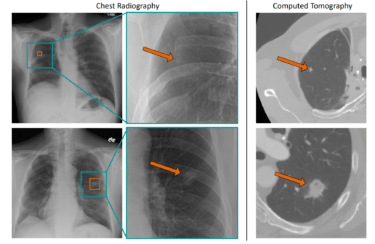
KI in der Medizin setzt aktuell häufig auf manuell gelabelte Datensätze. Eine neue Methode überwindet diese Einschränkung mit selbst-überwachtem Lernen für Röntgenaufnahmen.
KI-Systeme für die medizinische Diagnostik von Röntgenaufnahmen des Brustkorbs unterstützen die Radiologie dabei, Lungenkrankheiten oder Krebs erkennen. Für das Training der KI-Modelle greifen Forschende auf Algorithmen des überwachten Lernens zurück. Diese Trainingsmethode hat sich auch in anderen Bereichen der Bildanalyse bewährt und gilt als zuverlässig.
Doch das überwachte Lernen benötigt von Menschen gelabelte Daten. In der Medizin ist das ein großes Problem: Die Interpretation medizinischer Aufnahmen ist zeitaufwendig und erfordert teure menschliche Expert:innen. Die Daten sind daher ein Flaschenhals für die Verbesserung und Ausweitung der KI-Diagnostik auf andere Erkrankungen. Einige Forschende experimentieren daher bereits mit KI-Modellen, die mit ungelabelten Daten vortrainiert werden und anschließend mit den seltenen von Expert:innen gelabelten Daten nach trainiert werden.
KI-Bildanalyse setzt vermehrt auf selbst-überwacht trainierte Modelle
Außerhalb der medizinischen Diagnostik haben sich derweil selbst-überwacht trainierte Modelle für die Bildanalyse durchgesetzt. Frühe Beispiele wie Metas SEER oder DINO und Googles Vision Transformer zeigten das Potenzial der Kombination aus selbst-überwachten Trainingsmethoden und riesigen, ungelabelten Datensätzen.
Durchbrüche wie OpenAIs CLIP verdeutlichten zusätzlich die zentrale Rolle, die mit Bildern und zugehörigen Textbeschreibungen multimodal trainierte Modelle in der Bildanalyse und -generierung spielen können. Im April zeigte Google mit der LiT-Methode ein multimodales Modell, das die Qualität explizit für den ImageNet-Benchmark überwacht trainierte Systeme erreichte.
Forschenden der Harvard Medical School und der Stanford University ist nun ein großer Fortschritt gelungen: Sie veröffentlichen CheXzero, ein selbst-überwacht trainiertes KI-Modell, das aus Bild- und Textdaten selbstständig lernt, Erkrankungen zu identifizieren.
CheXzero lernt aus Röntgenaufnahmen und klinischen Aufzeichnungen
Die Forschenden trainierten CheXzero mit mehr als 377.000 Röntgenaufnahmen des Brustkorbs und mehr als 227.000 dazugehörige klinische Aufzeichnungen. Das Team testete das Modell anschließend mit zwei separaten Datensätzen zweier verschiedener Einrichtungen, eine außerhalb der USA, um Robustheit bei unterschiedlicher Terminologie sicherzustellen.
In den Tests identifizierte ChexZero erfolgreich Pathologien, die nicht explizit in den von menschlichen Expert:innen angefertigten Notizen erwähnt wurden. Das Modell übertraf dabei andere selbst-überwachte KI-Werkzeuge und näherte sich der Genauigkeit menschlicher Radiolog:innen.
"Wir befinden uns in den Anfängen der nächsten Generation medizinischer KI-Modelle, die in der Lage sind, flexible Aufgaben durch direktes Lernen aus Texten zu erfüllen", so Studienleiter Pranav Rajpurkar, Assistenzprofessor für biomedizinische Informatik am Blavatnik Institute der HMS. "Bislang waren die meisten KI-Modelle auf die manuelle Kommentierung riesiger Datenmengen - bis zu 100.000 Bilder - angewiesen, um eine hohe Leistung zu erzielen. Unsere Methode benötigt keine solchen krankheitsspezifischen Annotationen."

CheXzero entfernt Daten-Flaschenhals für medizinische KI-Systeme
CheXzero lerne, wie Konzepte im unstrukturierten Text mit visuellen Mustern im Bild übereinstimme, so Rajpurkar. Die Methode eignet sich daher auch für andere bildgebende Verfahren, etwa CT-Scans, MRTs oder die Echokardiografie.
"CheXzero zeigt, dass die Genauigkeit komplexer medizinischer Bildinterpretationen nicht länger von der Gnade großer, beschrifteter Datensätze abhängen muss", so der Erstautor der Studie, Ekin Tiu, ein Student in Stanford und Gastforscher an der HMS. "Wir verwenden Röntgenaufnahmen der Brust als Beispiel, aber in Wirklichkeit lässt sich die Fähigkeit von CheXzero auf eine Vielzahl von medizinischen Situationen übertragen, in denen unstrukturierte Daten die Norm sind, und verkörpert das Versprechen, den Engpass bei der Beschriftung großer Datenmengen zu umgehen, der den Bereich des medizinischen maschinellen Lernens geplagt hat."
Code und Modell sollen öffentlich auf GitHub verfügbar gemacht werden und werden von einer wissenschaftlichen Veröffentlichung in Nature begleitet.