
Eine neue KI kann Bilder anhand sprachlicher Beschreibungen erträumen. Die Technik steht erst am Anfang, aber könnte einmal unseren Umgang mit Medien revolutionieren.
Forscher von Google, der Universität Kalifornien, Merced und der Yonsei University haben die KI RetrieveGAN gebaut, die Bilder anhand von Beschreibungen generiert. Diese KI-gestützte Bildgenerierung könnte in der Kunst, im Design oder Marketing genutzt werden, um Motive und Bildwelten auf Zuruf automatisch erstellen zu lassen.
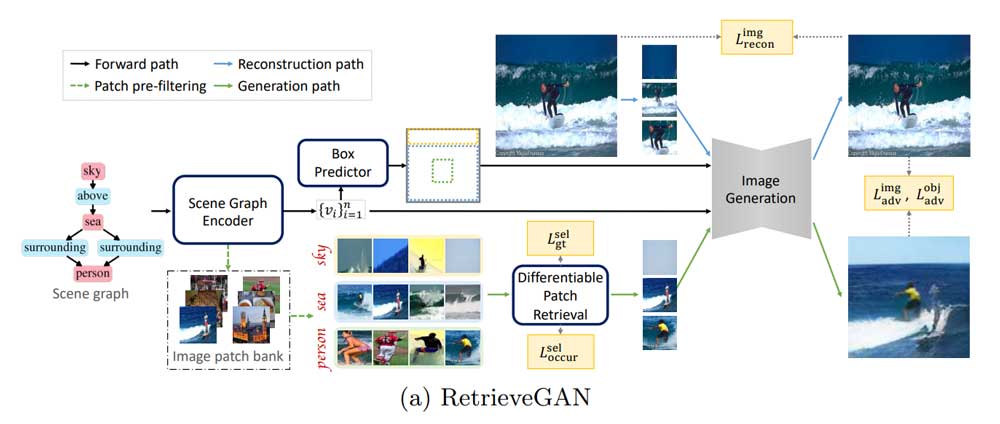
RetrieveGAN arbeitet in drei Schritten: Beschreibung verstehen, passende Bildbausteine zusammensuchen und Bild generieren.
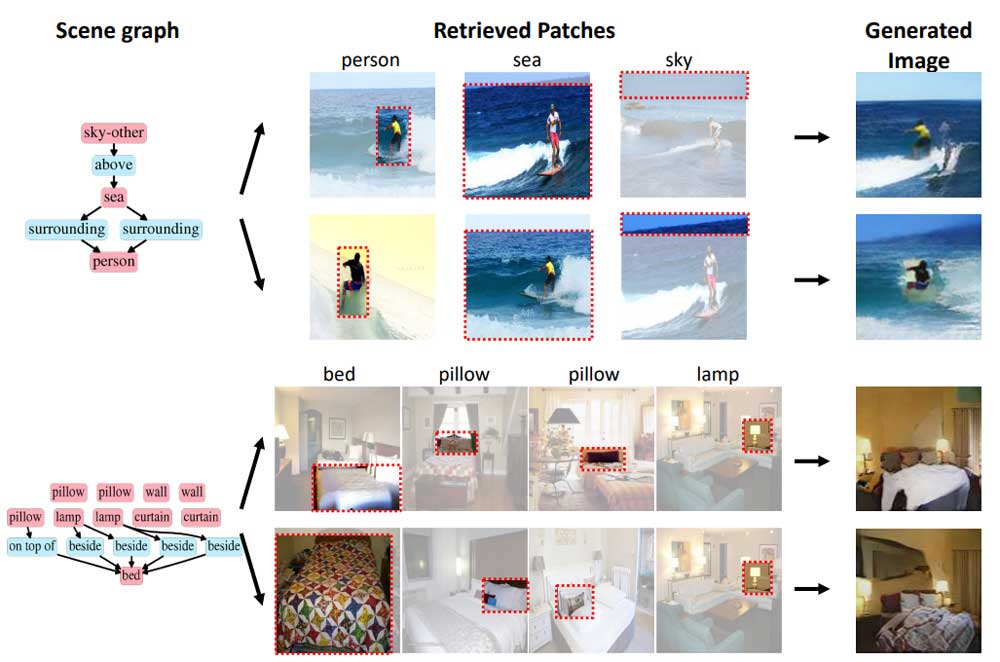
Im ersten Schritt bekommt die KI einen sogenannten Szenengraphen. In dem werden in natürlicher Sprache Objekte und Relationen in einer Art Baumdiagramm dargestellt.
Aus dem Graphen leitet die KI dann die Objekte und ihre Positionierung im gewünschten Bild ab. Aus den Informationen erstellt sie einen ersten Entwurf, der lediglich aus Begrenzungsboxen besteht, die die Position der einzelnen Objekte sichert.
Im zweiten Schritt sucht die KI in einer Datenbank nach Bildausschnitten der gewünschten Objekte, etwa einen Surfer, ein Stück blauen Himmel, einen Strand und einen Meerabschnitt. Im letzten Schritt fügt ein GAN-Netzwerk das Bild aus den Begrenzungsboxen und Bildausschnitten zusammen.
RetrieveGAN lernt visuelle Zusammenhänge
Ähnliche KIs existieren schon, doch die Macher von RetrieveGAN versprechen bessere Resultate. Der Grund: Die KI lernt, zusammenpassende Bildausschnitte auszuwählen.
Die Forscher geben das Beispiel eines Feldspielers bei einer Sportart: In der Beschreibung wird womöglich nicht deutlich, ob es sich um einen Fußball- oder Baseballspieler handeln soll. Ältere Systeme können dann den Fehler machen, ein Baseballfeld mit Feldspielern beider Sportarten zu füllen.

RetrieveGAN lernt, solche Beziehungen zwischen verschiedenen Objekten einer Szene zu beachten und liefert so in sich stimmige Bilder. Trainiert wurde die KI dafür mit den zwei Bilddatensätzen COC-Stuff und Visual Genome. Anschließend wählt die KI ein Objekt nach dem anderen aus und achtet bei jedem Schritt darauf, dass die Inhalte zueinander und zur Anweisung passen.
Die Bilder sind häufig noch verwaschen, verzerrt oder mit geometrischen Absurditäten gespickt. Dennoch ist klar erkennbar, dass das Bild eine Repräsentation der ursprünglichen Beschreibung darstellt. Im Vergleich zu älteren Methoden schneide RetrieveGAN besser ab, schreiben die Forscher.
Beachtet man die sich schnell entwickelnden Generative Adversarial Networks (GAN-Geschichte), aus denen immer bessere Deepfakes entstehen, sind zeitnahe Verbesserungen der neuen KI-Technik wahrscheinlich. Die Forscher erhoffen sich Fortschritte, indem sie die Auswahl an Bildausschnitten erhöhen und den Lernprozess verbessern.
Titelbild: Tseng at al. | Via: Arxiv




