Das Non-Profit LAION veröffentlicht das aktuell beste CLIP Open-Source-Modell. Es könnte in Zukunft bessere Versionen von Stable Diffusion ermöglichen.
Im Januar 2021 veröffentlichte OpenAI Forschung zu einem multimodalen KI-System, das selbstüberwacht visuelle Konzepte aus natürlicher Sprache lernt. Das Unternehmen trainierte CLIP (Contrastive Language–Image Pre-training) mit 400 Millionen Bildern und zugehörigen Bildunterschriften.
CLIP wiederum trainierte parallel einen Bild- und einen Text-Encoder, um die korrekten Paarungen von Bild und Unterschrift aus einer Reihe von Trainingsbeispielen vorherzusagen.
OpenAI veröffentlichte die größeren Versionen von CLIP in Stufen bis zum April 2022. In der Open-Source-Community entstanden parallel Bemühungen, CLIP zu reproduzieren.
CLIP nimmt zentrale Rolle in generativen KI-Modellen ein
CLIP kann nach dem Training Repräsentationen von Bildern und Text berechnen, sogenannte Embeddings, und anschließend erfassen, wie ähnlich sich diese sind. Das Modell kann so für eine Reihe von Aufgaben wie Bildklassifizierung oder dem Finden ähnlicher Bilder oder Texte verwendet werden. OpenAI nutzte CLIP, um von DALL-E 1 generierte Bilder unter anderem nach Qualität zu filtern.
In den nach DALL-E 1 entstandenen generativen KI-Modellen für Bilder nimmt CLIP häufig eine zentrale Rolle ein, etwa in CLIP+VQGAN, CLIP-guided diffusion oder StyleGAN-NADA. In diesen Beispielen berechnet CLIP den Unterschied zwischen einem Input-Text und einem etwa von einem GAN generierten Bild. Der Unterschied wird vom Modell minimiert und so ein besseres Bild erzeugt.
In neueren Modellen, wie DALL-E 2 oder Stable Diffusion, sind CLIP-Encoder dagegen direkt im KI-Modell integriert und ihre Embeddings werden von den verwendeten Diffusion Modellen verarbeitet. Forschende aus Kanada zeigten zudem kürzlich, wie CLIP helfen kann, 3D-Modelle zu generieren.
LAION veröffentlicht leistungsstarkes OpenCLIP
Nun veröffentlicht das Non-Profit LAION drei große OpenCLIP-Modelle. LAION (Large-scale Artificial Intelligence Open Network) trainierte zwei der Modelle mit finanzieller Unterstützung von Stability AI, dem Start-up hinter Stable Diffusion.
Eines der Modelle wurde zudem auf dem JUWELS Booster Supercomputer trainiert. Das Forschungsnetzwerk veröffentlichte zuvor vorwiegend Open-Source-Datensätze wie LAION-5B, einem gigantischen Bilddatensatz mit zugehörigen Unterschriften (5,8 Milliarden Bild-Text-Paare).
Die jetzt veröffentlichten OpenCLIP-Modelle (L/14, H/14 und g/14) gehören zu den bisher größten und leistungsstärksten CLIP Open-Source-Modellen. Für das Training setzte das Team auf den etwas kleineren LAION-2B-Datensatz.
Das H/14-Modell erreicht im ImageNet-Benchmark eine Top-1-Genauigkeit von 78,0 Prozent und bei MS COCO eine Genauigkeit von 73,4 % im Zero-Shot-Bildretrieval Benchmark MS COCO bei Recall@5. Nach aktuellem Stand ist es damit das beste Open-Source CLIP-Modell.
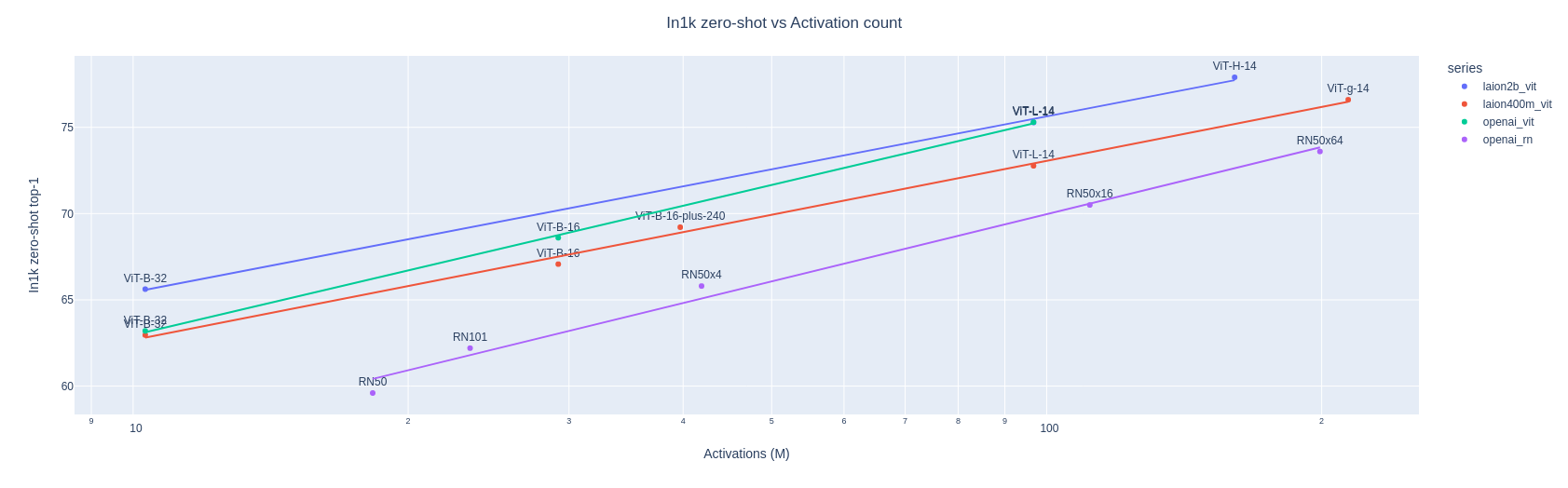
LAION zeigt mit dem Training zudem, dass CLIP-Modelle wie andere Transformer-Modelle mit Trainingsdaten und Größe in ihrer Fähigkeit skalieren.
LAIONs Modelle könnten bessere generative KI-Modelle ermöglichen
Die Modelle wurden auf bis zu 824 Nvidia A100 GPUs mit 40 Gigabyte VRAM trainiert. Während des Trainings habe man mehrere interessante Probleme aufgedeckt und gelöst, darunter die Identifikation fehlerhafter GPUs, die Rolle großer Batch-Größen im Training und die Auswirkungen verschiedener Floating-Point-Formate auf die Trainingsstabilität.
LAIONs neue CLIP-Modelle können jetzt für zahlreiche Anwendungen kostenlos verwendet werden. Auch Stable Diffusion könne von den neuen Modellen profitieren, so das Team. Der Nachweis der Skalierungseigenschaften von CLIP öffne zudem den Weg zu weiteren Verbesserungen. So plant LAION etwa, einen mehrsprachigen Text-Encoder in CLIP zu integrieren und zu skalieren.
Abseits der Bildverarbeitung könne die Idee hinter CLIP auf andere Modalitäten ausgeweitet werden, etwa für Text-Audio-Alignment, schreibt das Team. Das Projekt läuft bereits und trägt den schönen Namen CLAP. Die OpenCLIP-Modelle sind über GitHub und bei HuggingFace verfügbar.