
Titelbild: Twitter.com/bilalfarooqu
Trotz aller Erfolgsmeldungen und beeindruckender Videos – wirklich autonome Roboter brauchen noch ein Weilchen.
Künstliche Intelligenz (KI) erkennt Katzen, generiert Videos, übersetzt Texte oder nimmt es mit Starcraft-Profis auf. Dem KI-gesteuerten Super-Roboter, der sich menschengleich in jeder Situation zurechtfindet, steht also nichts mehr im Weg. Oder?
Ein Blick in die Schlagzeilen zeichnet ein anderes Bild. Dort wird von Salto-schlagenden Roboterhunden und würfeljonglierenden Robohänden berichtet. Nett. Mitunter beeindruckend. Aber was ist mit funktionierenden Pflegerobotern? Oder echten Haushaltshilfen? Blecherne Bauarbeiter, die gefährliche Jobs im Alleingang regeln? Fehlanzeige. Selbst das autonome Auto setzt im Notfall noch immer auf menschliche Unterstützung.
Die Parkour-Fähigkeiten des Boston-Dynamics-Roboters Altas gingen durch die Medien. Doch so bald wird er nicht durch unsere Städte flitzen.
Woher kommt dieses Missverhältnis zwischen brillanten Computer-KIs und orientierungslosen Echtwelt-Robotern? Die kurze Antwort: Die echte Welt ist kompliziert und vielleicht sogar unberechenbar. Die lange Antwort folgt jetzt.
Roboter kontrollieren leicht gemacht
Egal ob Industrieroboter, SpotMini oder Uber-Car – jede dieser Maschinen läuft mehr oder weniger autonom. Dabei gilt: Einfache Aufgaben und gut kontrollierbare Umgebungen erleichtern ihre Eigenständigkeit.
In der Industrie sind diese Bedingungen häufig gegeben: Roboter setzen Fahrzeuge zusammen oder sortieren Waren in den großen Lagerhallen von Logistikunternehmen.
Dort ist es leicht, strukturierte Umgebungen zu schaffen: Arbeitsabläufe lassen sich genau planen und unerwartete Veränderungen in der Umgebung sind nicht zu erwarten.

Diese Industrieroboter werden von Hand programmiert und kalibriert, erledigen nur eine Aufgabe und sind oft auf teure Sensoren angewiesen. Ihr Nachteil: Verändert sich ihre Arbeitsumgebung, sind sie nutzlos.
Mehr Bewegung, mehr Welt
Bewegt sich ein Roboter durch die Welt, wird es kompliziert. Mehr Gelenke, mehr Sensoren und vor allem: mehr Stolpersteine.
Wer agile Roboter bauen will, steht vor zwei Herausforderungen: Eine sich ständig verändernde Umgebung und die Balance des Roboters selbst.
Wie bei den Industrierobotern ist eine Programmierung per Hand möglich. Die ausgezeichnete Balance der Roboter von Boston Dynamics beweisen das. Doch die Handarbeit ist aufwendig und teuer.
Für Demonstrationen werden die Roboter oft von einem Menschen ferngesteuert, das erhöht die Stolpergefahr. Doch auch autonome Roboter ohne menschliche Beteiligung sind nicht automatisch unfehlbar.
Der menschliche Steuermann und wie leicht eine Lampe zum Hindernis werden kann.
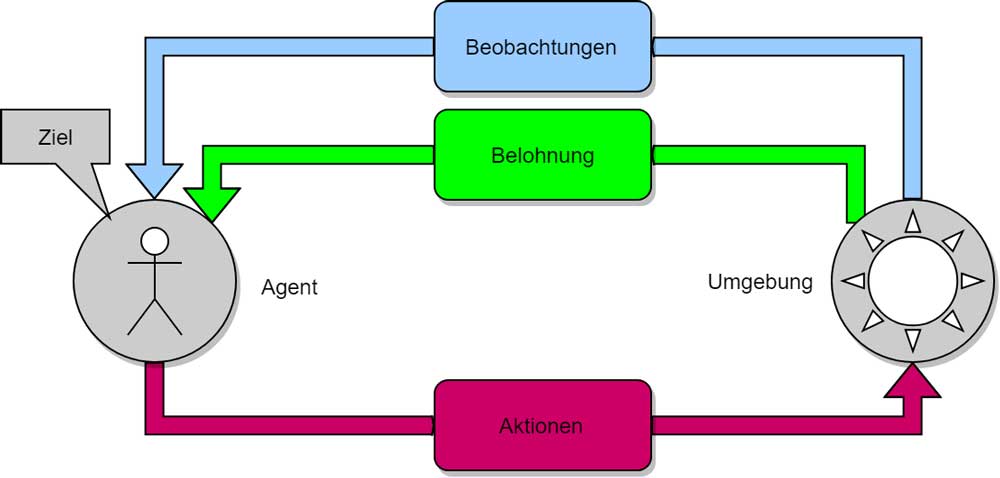
Bestärkendes Lernen als Lösung
Exakt hier setzt die Lernmethode „bestärkendes Lernen“ an: Mit ihr kann eine KI die Steuerung des Roboters und den Umgang mit der Umgebung automatisiert lernen – indem sie wie ein Mensch die Umgebung erforscht und Erfahrungen macht.
Ein großer Vorteil der Methode: Sie kann Probleme lösen, für die noch kein Lösungsansatz existiert.
Deepmind-KIs AlphaZero und AlphaStar beweisen, dass Künstliche Intelligenz mit dieser Lernmethode in speziellen Anwendungsszenarien außerordentliche Ergebnisse erzielen kann. Alphastar schlug als erste KI kürzlich Profispieler im komplexen Strategiespiel Starcraft. Das erforderte strategisches Geschick und Planung.
Echtwelt-Simulation dringend gesucht
Wendet man das bestärkende Lernen auf Roboter in realen Umgebungen an, zeigt sich ein Problem: Es dauert mitunter Monate, komplexe Interaktionen in der echten Welt zu erlernen – sofern die Hardware all die Fehlschläge überlebt. Die Versuch-und-Irrtum-Methode kann für die Umwelt sogar gefährlich sein, denn vor dem Erfolg stehen endlos viele Fehlschläge.
Die Lösung: Die KI trainiert zuerst in einer virtuellen Umgebung einen virtuellen Roboter. Das verhindert Kollateralschäden und es können Dutzende Agenten gleichzeitig in hohem Tempo lernen, da die VR-Simulation im Unterschied zur echten Welt vorgespult werden kann. Anschließend wird das in der virtuellen Welt antrainierte Wissen auf einen realen Roboter übertragen.
Erste Erfolge gibt es bereits: 2017 lernte Deepminds KI digital laufen und 2018 brachte OpenAI einer Roboterhand das Jonglieren bei.
OpenAIs KI hatte zuerst digital trainiert und ihre Fähigkeiten anschließend in der echten Welt bewiesen. OpenAI zeigte damit, dass die Übertragung von in der Simulation gelernten Fähigkeiten in die echte Welt möglich ist.
(Noch) kein Allheilmittel
Trotz dieser Fortschritte sind die Fähigkeiten aktueller Roboter eingeschränkt. Woran liegt das?
Die Kombination aus bestärkendem Lernen und virtuellem Training kann zwar recht umsichtige, agile Roboter schaffen, doch es gibt ein Problem: In komplexen Umgebungen sind eindeutige Belohnungen für gutes Verhalten selten. Die KI braucht die Belohnungen aber zur Orientierung.
Außerdem ist die Übertragung der gelernten Fähigkeiten in die echte Welt kompliziert, weil Simulation und Realität dann eben doch nicht exakt übereinstimmen. Eine wirklich originalgetreue Simulation realer Parameter ist mit hohem Programmieraufwand verbunden und ab einer gewissen Komplexität derzeit schlicht nicht möglich.
Roboter stolpern über die Realitätslücke
Selbst die beste Simulation bildet die Realität nicht perfekt ab. Eine KI, die nur mit synthetischen Daten trainiert wird, kommt daher in der echten Welt nur bedingt zurecht. KI-Forscher haben für dieses Problem einen Namen: Es ist die Realitätslücke.
Ein Beispiel: Schon die vollumfängliche Simulation des simplen Geschicklichkeitsspiels „Jenga“ brachte MIT-Forscher an ihre Grenzen. Wie soll dann erst ein Einkaufsroboter trainiert werden, der sich unter Menschen bewegt?

Häufig scheitern KIs nach dem Training schon an der visuellen Wahrnehmung der Welt, die die Grundlage vieler maschineller Handlungen ist. Hier kann zwar mit separatem Training nachgeholfen werden.
Allerdings können selbst hochspezialisierte Bilderkennungs-KIs leicht ausgetrickst werden oder haben Probleme, Gegenstände unter wechselnden Bedingungen (Licht, Perspektive) zu erkennen.
Ein weiteres Problem: Mit bestärkendem Lernen trainierte KIs sind besonders gut darin, Fehler in Simulationen auszunutzen, wenn sie der eigenen Sache dienen. Immer wieder gibt es Fälle, in denen eine KI besonders gut abschneidet, da sie eine vom Entwickler nicht vorgesehene Abkürzung entdeckt hat. Bei einem Computerspiel mag das charmant sein. In der Realität könnten solche Unwägbarkeiten Menschenleben kosten.
Brückenschlagen zwischen Simulation und Realität
Es gibt erste Ansätze, wie die Realitätslücke für gewisse Aufgaben überwunden werden und bestärkendes Lernen für Echtwelt-Roboter sinnvoll genutzt werden kann.
Einer dieser Ansätze: Eine KI soll die Feinheiten der Umwelt automatisiert lernen und anschließend die Trainingssimulation für ihre KI-Kollegen erstellen. Das würde den Programmieraufwand für komplexe Simulationen senken. Anfang des Jahres brachte sich etwa ein Roboterhund mit dieser Methode das Laufen bei.
Ein weiterer Ansatz: Die KI sammelt Erfahrungen und generalisiert sie zu Konzepten. So ähnlich orientiert sich der Mensch. Ein Beispiel ist der zuvor erwähnte „Jenga“-Roboter: Da die Forscher das Turmklötzchenspiel in seiner feinfühligen Gesamtheit nicht akkurat genug simulieren konnten, trainierten sie die KI in der Realität.
Auf diese Art brachten sie der KI das Abstrahieren bei: Sie lernte, Klötzchen in Kategorien wie „leicht zu bewegen“ oder „schwer zu bewegen“ aufzuteilen. So entwickelte sie eine rudimentäre Vorstellung physikalischer Prinzipien.
OpenAIs Jenga-KI brauchte nur etwa 300 reale Trainingseinheiten, bis sie das Spiel auf menschlichem Niveau beherrschte. Tausende Trainingseinheiten in einer Simulation führten im Vergleich zu einem schlechteren Ergebnis.
Versuch-und-Irrtum ist ineffizient
Bei komplexen Aufgaben ist allerdings nicht allein die Realitätslücke eine Herausforderung: Die einfache Versuch-und-Irrtum-Methode ist für manche Aufgaben schlicht ungeeignet. Das lässt sich gut an alten Computerspielen veranschaulichen.
Klassiker wie „Pong“ oder „Space Invaders“ belohnen den Spieler für beinahe jede Handlung mit Punkten. So erhält er direktes Feedback zu erfolgreichen Aktionen. Diesen Hebel nutzen Forscher, um einer KI das Siegen beizubringen.
Doch das jahrzehntealte Atari-Spiel „Montezumas Revenge“ hebelt diesen simplen Mechanismus aus. Während KIs mittlerweile in nahezu allen Atari-Spielen weit über menschlichem Niveau spielen, scheitern sie immer wieder am ersten Level des Klassikers.
Das Problem: Wo andere Spiele der KI für nahezu jede Aktion unmittelbar Rückmeldung geben, sind Erfolge in Montezumas Revenge rar gesät.
Im Beispielbild: Die KI erhält vom Spiel erst durch Aufnahme des Schlüssels positive Bestärkung. Der Weg dorthin ist kompliziert und jeder falsche Schritt führt zum Tod des Charakters.

Solange die KI nur zufällige Aktionen wie „links“, „hoch“, „runter“ oder „springen“ ausführen kann, ist ihre Chance auf Erfolg extrem gering. Die Versuch-und-Irrtum-Methode stößt so an ihre Grenze: Die KI erhält kein positives Feedback und lernt daher nicht.
Natürlich können Forscher tricksen: Eine Montezuma-KI von OpenAI wurde einfach für jeden Pixel belohnt, den sie neu entdeckte. Die Forscher beschrieben das als Neugierdefunktion. Die KI spielte Montezuma erfolgreicher als jede andere Künstliche Intelligenz zuvor. Sie beendete das Spiel allerdings nicht.
Dieser Erfolg gelang OpenAI mit einer weiteren KI, bei der die Forscher auf eine Kombination aus bestärkendem und imitierendem Lernen setzten.
Die KI lernte also nach dem Versuch-und-Irrtum-Prinzip und zusätzlich anhand einer menschlichen Demonstration, die von einer Belohnung ausgehend schrittweise zurückgespult wurde.
So benötigte die KI immer nur wenige Schritte zur Belohnung. Den erfolgreichen Weg speicherte sie ab. Bei jedem neuen Versuch startete sie etwas weiter vorne - bis sie irgendwann das gesamte Spiel von hinten nach vorne durchgespielt hatte.

Am Ende lag die Punktzahl der KI über dem menschlichen Highscore. Allerdings manipulierte sie das Spiel: Sie entdeckte einen Fehler im Emulator und verdoppelte einen Schlüssel für die zweifache Belohnung - das zuvor erwähnte Pfuschproblem, das in der echten Welt im schlechtesten Fall zur Auslöschung der Menschheit führen könnte, wenn eine KI zum Beispiel bemerkt, dass der schnellste Weg zur Klimarettung die Beseitigung aller Menschen ist.
Bestärkendes Lernen keine Allzwecklösung
Was für Montezumas Revenge zutrifft, gilt auch für die echte Welt: Komplexe Ziele sind schwer durch kleine, zufällige Schritte zu erfüllen.
Bestärkendes Lernen ist daher trotz des großen Potenzials weit davon entfernt, eine Allzwecklösung für jede Aufgabe zu werden. Komplexe Aufgaben in unberechenbaren Umgebungen in der realen Welt zu lösen, bleibt auf lange Sicht eine Herausforderung der KI-Branche.
Bestärkendes Lernen wird dennoch die treibende Kraft in der Robotik werden, weil es viele Varianten gibt, die zusammengenommen zum gewünschten Resultat führen können, nämlich Robotern, die sich wie Menschen in der Realität orientieren. Und zwar zuverlässig.
„Multi Sensory Learning“ macht das Training durch mehr Daten effizienter, „Hierarchical Reinforcement Learning“ lässt KIs die Ziele selbst wählen, „Transfer Learning“ erleichtert die Übertragung des Gelernten in neue Situationen und beim „Imitation Learning“ nimmt sich die KI den Mensch als Vorbild. Welcher Ansatz sich letztlich durchsetzt, ist noch nicht absehbar – wahrscheinlich wird es eine Mischung.





