Kostenloser lokaler Chatbot von Nvidia mit neuen KI-Modellen, Bildersuche und Spracheingabe
Update –
- Neue Funktionen ergänzt
Update vom 1. Mai 2024:
Nvidia aktualisiert seinen experimentellen Chatbot ChatRTX für RTX-GPU-Besitzer mit weiteren KI-Modellen, darunter Gemma von Google, ChatGLM3 und OpenAIs CLIP-Modell für die Fotosuche. Darüber hinaus unterstützt ChatRTX nun auch Sprachanfragen über OpenAIs Whisper-Modell.
ChatRTX ist als 36-GB-Download auf Nvidias Website verfügbar und erfordert eine RTX-30- oder 40-Series-GPU mit mindestens 8 GB VRAM.
Update vom 13. Februar 2024:
"Chat with RTX" von Nvidia steht ab sofort als kostenloser Download zur Verfügung. Der Chiphersteller empfiehlt mindestens eine Geforce-Grafikkarte der RTX 30-Serie mit 8 GB VRAM und 16 GB Arbeitsspeicher sowie Windows 11 als Betriebssystem. Der Download ist rund 35 GB groß. Über die Sprachmodelle Llama 2 und Mistral kann man dann eigene Dateien sowie YouTube-Video-Transkripte lokal "chatbar" machen.
Ursprünglicher Artikel vom 11. Januar 2024:
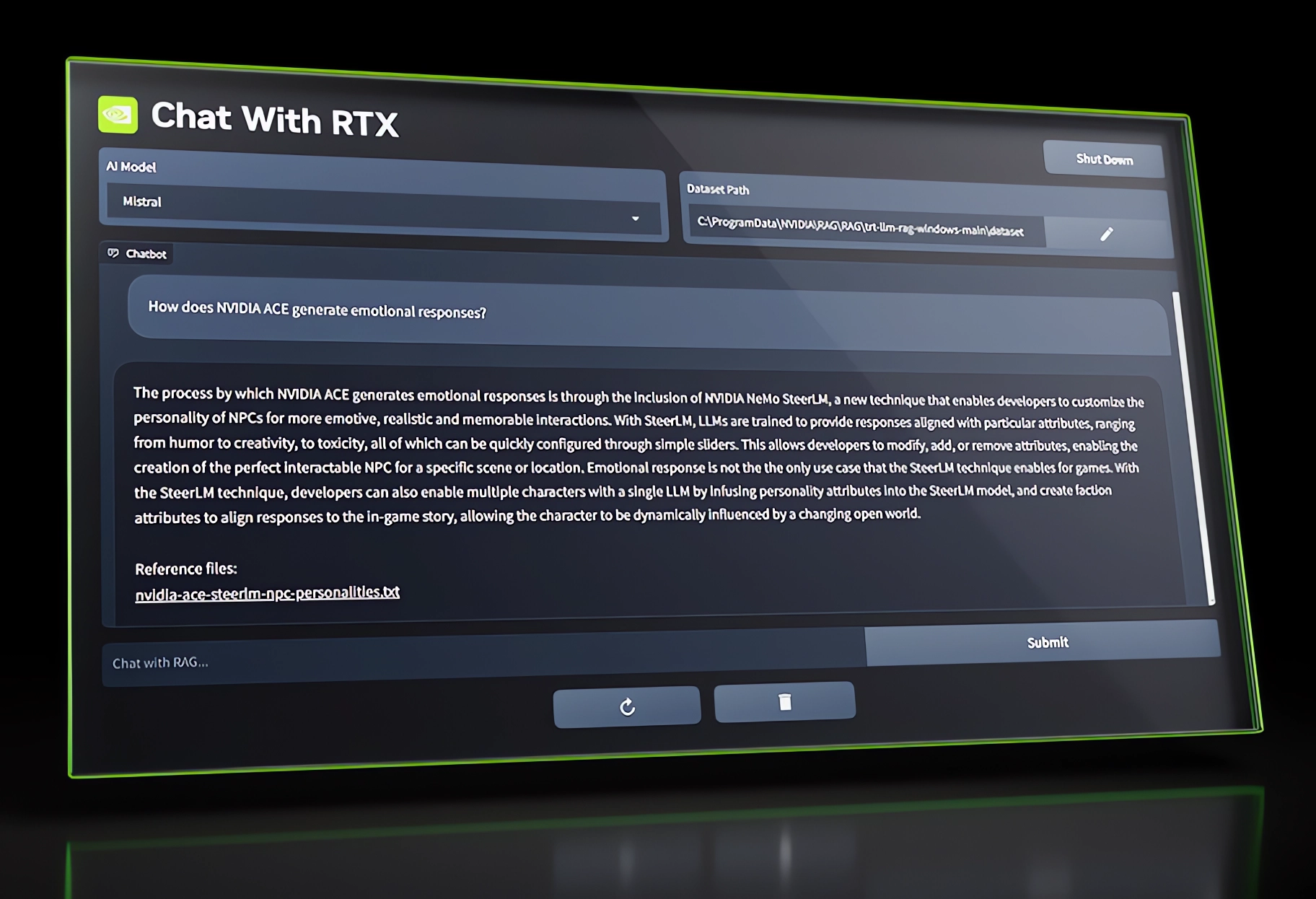
Nvidias "Chat with RTX" ist ein kostenloser, lokaler Daten-Chatbot
Nvidia hat eine neue Demo-Anwendung namens Chat with RTX angekündigt, mit der Benutzer ein LLM mit eigenen Inhalten wie Dokumenten, Notizen, Videos oder anderen Daten zu personalisieren.
Die Anwendung nutzt Retrieval-Augmented Generation (RAG), TensorRT-LLM und RTX-Beschleunigung, um Nutzern die Möglichkeit zu geben, einen benutzerdefinierten Chatbot zu befragen und schnell und sicher kontextbezogene Antworten zu erhalten.
Der Chatbot läuft lokal auf einem Windows RTX PC oder einer Workstation und bietet somit zusätzlichen Datenschutz im Vergleich zur Cloud-Variante.
Chat with RTX unterstützt eine Vielzahl von Dateiformaten, darunter Text, pdf, doc/docx und xml. Die Benutzer können einfach die entsprechenden Ordner an die Anwendung anhängen, die dann die Dateien in die Bibliothek lädt.
Darüber hinaus können Nutzer die URL einer YouTube-Playlist angeben, und die Anwendung lädt die Transkripte der Videos in der Playlist und macht sie chatfähig. Google Bard bietet eine ähnliche Funktion, aber nur mit einem Google-Konto in der Google Cloud. Chat with RTX verarbeitet das Transkript lokal.
Video: Nvidia
Nvidia bietet hier eine Registrierung an, um benachrichtigt zu werden, sobald die Software verfügbar ist.
Entwickler können sofort loslegen
Entwickler können sofort loslegen, denn die Chat with RTX Tech Demo basiert auf dem TensorRT-LLM RAG Developer Reference Project, das auf GitHub verfügbar ist. Entwickler können diese Referenz laut Nvidia verwenden, um ihre eigenen RAG-basierten Anwendungen für RTX zu entwickeln und bereitzustellen, die durch TensorRT-LLM beschleunigt werden.
Neben Chat with RTX stellte Nvidia auf der CES auch RTX Remix vor, eine Plattform zur Erstellung von RTX-Remastern von Spieleklassikern, die im Januar als Beta-Version verfügbar sein soll.
Außerdem wurden die Nvidia ACE Microservices angekündigt, die Spiele mit intelligenten und dynamischen digitalen Avataren ausstatten, die auf generativer KI basieren.
Darüber hinaus wurde die TensorRT Beschleunigung für Stable Diffusion XL (SDXL) Turbo und Latent Consistency Modelle veröffentlicht, die eine Leistungssteigerung von bis zu 60 Prozent bringen soll.
Eine aktualisierte Version der Stable Diffusion WebUI TensorRT Erweiterung mit verbesserter Unterstützung für SDXL, SDXL Turbo, LCM - Low-Rank Adaptation (LoRA) ist jetzt verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.