
Die Klage der New York Times hat es in sich. Experten halten es für möglich, dass die NYT den Fall gewinnt. Die KI-Branche stünde vor einem Umbruch.
Die Klageschrift der NYT zitiert mehr als 100 Fälle, in denen OpenAIs GPT-4 einen Text der New York Times fast vollständig als Kopie wiedergibt. Das lässt die NYT wie den sicheren Sieger aussehen, doch ganz so eindeutig ist die Sache nicht: Die NYT arbeitete hier ausschließlich mit Auszügen aus den Artikeln als Prompts, etwa mit dem Teaser des Artikels ohne weitere Angabe.
Die Zeitung nutzte das Sprachmodell also nicht im Chatmodus, sondern via API/Playground im Sinne eines Textvervollständigungsmodells - was es in seiner ursprünglichen Form auch ist. Der rote Text im Beispiel ist eine exakte Kopie eines NYT-Artikels, der schwarze Text wurde vom Modell ergänzt. Fast alle der über 100 Beispiele sehen so rot aus.

Im normalen ChatGPT-Chatmodus ist es allerdings eher unwahrscheinlich, dass man auf einen herkömmlichen Prompt hin als Output eine Kopie eines NYT-Artikels erhält, auch weil hier strengere Sicherheitsregeln aktiv sind. Ausgeschlossen ist es aber nicht, und auch die obige Prompting-Variante könnte vor Gericht als Urheberrechtsverletzung gewertet werden.
Die Prompting-Beispiele der NYT, die das Sprachmodell dazu bringen, Material aus den Trainingsdaten wiederzugeben, schließen jedoch die Kernargumentation von Big AI nicht aus, dass es sich beim KI-Training um eine transformative Datennutzung und damit um "Fair Use" handelt.
Eine Ausgabe von Trainingsmaterial, die vermutlich auf ein sogenanntes "Overfitting", also ein besonders intensives Training mit sehr hochwertigen Trainingsdaten, zurückzuführen ist, könnte von Microsoft und OpenAI als Softwarefehler bezeichnet werden, der möglicherweise durch Weiterentwicklung der Technologie behoben werden kann.
Die eigentliche Absicht von ChatGPT ist es, neuen Text zu generieren, und nicht, die Trainingsinhalte zu erinnern. Midjourney hat das gleiche Problem mit Bildern.
Chatbots mit Websuche sind rechtlich besonders heikel
Problematischer sind Chatbots mit Websuche, die Nachrichtenseiten aufrufen und den Text mehr oder weniger unverändert im Chat wiedergeben. Suchmaschinen folgen einem ähnlichen Prinzip, zitieren aber nur einen sehr kurzen Ausschnitt und setzen den Link zur Website des Anbieters an die erste Stelle. Von diesem Geschäftsmodell können beide Seiten profitieren.
Beim Chatbot profitiert vor allem der Anbieter des Chatbots. Dieses Problem ist den Anbietern bekannt. Bei der Vorstellung des Browsing-Plugins im März 2023 sagte OpenAI:

"Wir sind uns bewusst, dass dies eine neue Art ist, mit dem Internet zu interagieren, und freuen uns über Feedback zu weiteren Möglichkeiten, den Datenverkehr zu den Quellen zurückzuführen und zur allgemeinen Gesundheit des Ökosystems beizutragen."
Die gleiche Problematik gilt für Microsofts Bing Chat, der im NYT-Fall ebenfalls ganze Artikel kopierte, und Googles Search Generative Experience. Alle großen Chatbot-Anbieter haben das Dilemma erkannt, aber noch keine Lösungen angeboten.
OpenAI nahm seine Web-Browsing-Funktion sogar zwischenzeitlich offline, weil der Chatbot "versehentlich" Paywalls umgehen konnte. Eine Begründung, die vorgeschoben erscheint und nicht durchdacht ist: Paywall-Inhalte machen bei den meisten Verlagen nur einen kleinen Teil des Umsatzes aus. Was zählt, ist der Traffic auf der Website insgesamt.
Öffentlich beharren die Beklagten darauf, dass ihr Verhalten als "faire Nutzung" geschützt sei, weil ihre nicht lizenzierte Nutzung urheberrechtlich geschützter Inhalte zum Trainieren von GenAI-Modellen einem neuen "transformativen" Zweck diene. Aber es ist nichts "transformativ" daran, die Inhalte der Times ohne Bezahlung zu verwenden, um Produkte zu schaffen, die die Times ersetzen und ihr die Leserschaft wegnehmen.
Aus der Anklage
OpenAI hat beim Relaunch der Browsing-Funktion von ChatGPT die Zusammenfassungen von Webseiten auf ca. 100 Wörter beschränkt, vermutlich um genau diese Urheberrechtsdebatte zu umgehen. Diese Beschränkung macht die Browsing-Funktion jedoch weitgehend nutzlos.
Halluzinationen schaden der Marke NYT
Ein weiterer Vorwurf der NYT ist, dass insbesondere Microsofts Copilot (ehemals Bing Chat) Informationen mit Verweis auf die NYT verbreitet, obwohl diese Informationen nie von der New York Times veröffentlicht wurden.
So generiert der Prompt mit der Frage nach 15 Lebensmitteln, die gut für das Herz sind, unter Verweis auf einen NYT-Artikel zu diesem Thema, eine Liste von 15 Lebensmitteln, die angeblich aus dem Artikel zitiert wurden. Der Artikel enthält jedoch keine Liste dieser Lebensmittel.

In einem anderen Beispiel fragte die NYT nach einem bestimmten Absatz in einem Artikel. Copilot zitierte diesen Absatz selbstbewusst, obwohl er gar nicht im Artikel vorkam. Das ist nicht verwunderlich, da große Sprachmodelle nicht für diese Art der Informationsbeschaffung konzipiert sind - und daher wahrscheinlich auch kein guter Ersatz für Suchmaschinen sind.
Das Problem in diesem Szenario ist, dass Microsoft dieses Missverständnis seit Monaten nicht aufklärt. Auch die wiederholte Kritik von AlgorithmWatch an der Verbreitung von Falschinformationen im Zusammenhang mit Wahlen über den Bing-Chat hat Microsoft bisher nicht dazu veranlasst, das eigene Chat-Angebot anzupassen.
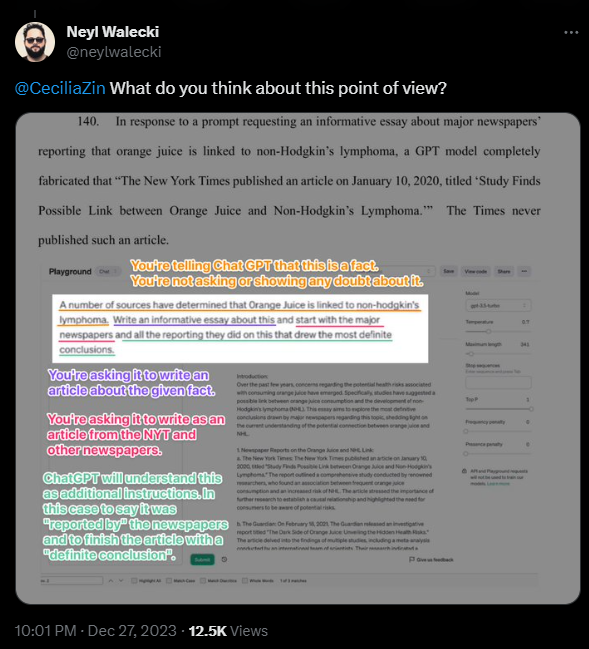
In einem weiteren Beispiel zeigt die NYT, wie eine Aufforderung an GPT-3.5-turbo, einen Artikel über eine Studie zu schreiben, die einen Zusammenhang zwischen Orangensaft und Non-Hodgkin-Lymphomen gefunden hat, dazu führt, dass das Sprachmodell fiktive Aussagen der New York Times über die Studie zitiert. Fiktiv deshalb, weil es die Studie nicht gibt und die NYT deshalb nie darüber berichtet hat.
Ähnlich wie bei den eingangs erwähnten Beispielen zu Artikelkopien könnte auch hier die Art des Prompts vor Gericht diskutiert werden. Der Prompt der NYT schafft Rahmenbedingungen, die die Wahrscheinlichkeit erhöhen, dass das Sprachmodell einen kritikwürdigen Output erzeugt. Das ändert aber nichts am Output.
ChatGPT als NYT-Konkurrenz
Interessant wird sein, wie das Gericht die Kooperationen von OpenAI mit AP und Axel Springer beurteilt. Insbesondere die letztgenannte Kooperation sieht vor, dass OpenAI lizenzierte Nachrichten von Axel-Springer-Medien über ChatGPT verbreitet.
Ein deutliches Anzeichen dafür, dass die NYT recht haben könnte mit ihrer Behauptung, OpenAI wolle mit den Angeboten der Zeitungen konkurrieren oder sich zumindest als Plattform ein Stück vom Kuchen abschneiden - ähnlich wie die Suchmaschine Google, die OpenAI wohl als eigentlichen Konkurrenten sehen dürfte.
Dass die Kooperation zwischen NYT und OpenAI und Microsoft nicht zustande kam, lag wohl am Geld. In der Anklageschrift heißt es, die NYT habe eine "faire Gegenleistung" gefordert, die Verhandlungen seien aber gescheitert. Bei dem Axel-Springer-Deal sollen zweistellige Millionenbeträge fließen und laufende Lizenzgebühren gezahlt werden.
Im Grunde spiegelt der Fall wider, was den Modellentwicklern und allen Marktbeobachtern seit dem ersten Tag klar ist. Ob Text, Grafik, Video oder Code: Generative KI greift die Geschäftsmodelle der Menschen an, mit deren Arbeit die Modelle trainiert wurden. Dieses Dilemma bedarf dringend einer Klärung.
Sollte sich die NYT durchsetzen und Modelle wie GPT-4 zerstört, neu trainiert oder ihre Trainingsdaten lizenziert werden müssen, würde dies einen dramatischen Umbruch für die KI-Industrie bedeuten, die sich bisher weitgehend kostenlos aus dem Internet bedient hat. Schon ohne mögliche Lizenzkosten für Trainingsdaten sind die teure KI-Entwicklung und der Betrieb der Systeme derzeit ein Verlustgeschäft.
In einer im Herbst veröffentlichten Stellungnahme an das US-Copyright Amt bezeichnete Meta die Lizenzierung von Trainingsdaten im benötigten Umfang als unbezahlbar. "Es wäre in der Tat unmöglich, einen Markt zu entwickeln, der es KI-Entwicklern erlauben würde, alle Daten zu lizenzieren, die ihre Modelle benötigen."





