OpenAIs neue Musik-KI "Jukebox" generiert ganze Bands

Der Sound ist noch ein bisschen stumpf - ansonsten liefert OpenAIs neue Musik-KI "Jukebox" teils eindrucksvolle Ergebnisse.
Im April 2019 zeigte OpenAI die Musik-KI "Musenet": Sie generiert Songs mit bis zu zehn unterschiedlichen Instrumenten nach einem vorgegebenen Stil.
Zur Auswahl stehen Künstler wie Mozart, Chopin, Lady Gaga oder Adele, deren Stile die KI kombinieren kann. Die generierten Songs bieten allerdings nur blechernen Midi-Klang, auch der Gesang fehlt.
Wir spulen ein Jahr vor: Mit "Jukebox" präsentiert OpenAI die nächste Evolutionsstufe maschinell-musikalischer Ambition. Die KI generiert ganze Songs mit Gesang. Die Texte wurden laut OpenAI kollaborativ von einem Sprachmodell und OpenAI-Forschern geschrieben.
Während Musenet noch mit unzähligen Midi-Dateien trainiert wurde, verwendete OpenAI für Jukebox echtes Liedgut. Insgesamt 1,2 Millionen Songs fischten die Forscher in guter Qualität aus dem Netz, immer in Kombination mit den Liedtexten.
In den Metadaten der Trainings-Songs stecken Informationen wie Künstler, Album, Genre, Veröffentlichungsjahr und typische Stimmungsbeschreibungen sowie Keywords für Playlists.
Die folgende Playlist ist eine Auswahl von KI-Songs mit neuen Texten, die OpenAI besonders gelungen findet. Alle Jukebox-Songs sind hier verfügbar.
KI-Musik ist schwierig
Die besondere Herausforderung bei der Konstruktion eines KI-Modells für Musikgenerierung sind die sogenannten Abhängigkeiten: Während sich beispielsweise eine Sprach- oder Text-KI auf die unmittelbar umliegenden Wörter oder Sätze beziehen kann, um passenden neuen Text zu generieren, muss eine Musik-KI musikalische Muster erkennen, die sich über mehrere Minuten ziehen können.
OpenAI hat dafür ein Zahlenbeispiel: Die eigene Text-KI GPT-2 nutze 10.000 Zeitintervalle, das sind einzelne Schritte in der Simulation. Die Game-KI Five liege bei mehreren Zehntausend Intervallen pro Partie. Ein typischer Song mit vier Minuten Länge habe circa zehn Millionen dieser Intervalle.
Die Forscher komprimierten daher die Internet-Songs in weniger komplexe Audiodateien, die für das KI-Training besser beherrschbar sind.
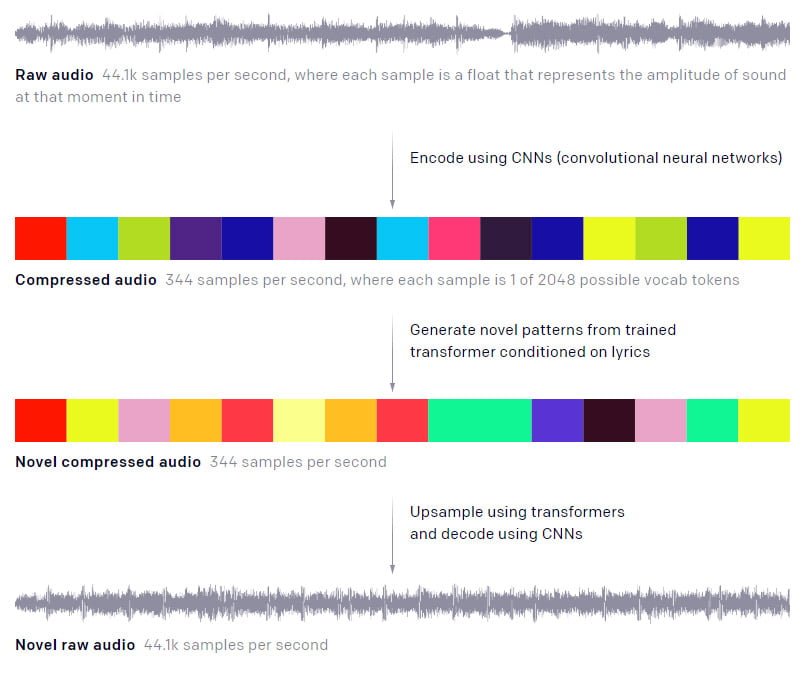
Auf Basis dieser komprimierten Songs wurden wiederum neue musikalische Muster in einem ähnlichen Stil generiert - ebenfalls in komprimierter Form. Dieser neue komprimierte Song wird dann in die Ausgangsqualität hochgerechnet. Der Prozess verursacht den dumpfen Klang der KI-Songs.
Mehr Informationen zum Trainingsprozess stehen im OpenAI-Blog.
Refrain geht noch nicht
Jukebox sei zwar qualitativ ein Schritt nach vorne bei KI-generierter Musik, schreiben die OpenAI-Forscher. Dennoch existiere eine "signifikante Lücke" zwischen der aktuellen Generation KI-Gedüdel und von Menschen gemachter Musik.
Grundlegende musikalische Zusammenhänge seien zwar erkennbar wie Akkordprogressionen. Sogar beeindruckende Soli kämen vor.
Aber übergreifende musikalische Strukturen wie Refrains seien nicht hörbar. Auch der Generierungsaufwand der KI-Songs ist hoch: Eine Song-Minute ist rund neun Stunden in der Berechnung.
OpenAI erwartet zukünftig weitere Fortschritte und mehr kreative Kollaboration zwischen Mensch und Künstlicher Intelligenz. KI-Modelle könnten Musikern beispielsweise mehr Kontrolle über die generierten Sounds geben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.