Google Deepmind veröffentlicht Open-Source-KI-Modelle mit Gemini-Technologie
Google hat mit Gemma eine neue Generation offener KI-Modelle vorgestellt, die auf den Erfahrungen mit den Gemini-Modellen aufbaut und auf eine verantwortungsvolle KI-Entwicklung abzielt.
Gemma wurde von Google DeepMind und anderen Google-Teams entwickelt, um Entwicklern und Forschern weltweit zugängliche, leistungsfähige Modelle zur Verfügung zu stellen. Die Modelle sind in zwei Größen erhältlich: Gemma-2B und Gemma-7B, jeweils mit vortrainierten und instruktionsbasierten Varianten.
Die Gemma-Modelle wurden mit bis zu 6 Billionen überwiegend englischsprachigen Tokens aus Webseiten, Mathematikaufgaben und Code trainiert, wobei ähnliche Architekturen, Daten und Trainingsmethoden wie bei der Gemini-Modellfamilie verwendet wurden. Im Gegensatz zu Gemini ist Gemma nicht multimodal und wurde auch nicht für "Spitzenleistungen" bei mehrsprachigen Aufgaben trainiert.

Laut dem technischen Bericht von Google übertrifft Gemma in 11 von 18 textbasierten Aufgaben ähnlich große, offene Modelle wie LLaMA 2 mit 7 und 13 Milliarden Parametern sowie Mistral-7B. Der größte Vorsprung ist in den Bereichen Mathematik und Coding zu beobachten, auch wenn hier zu größeren Modellen insgesamt noch viel Luft nach oben zu sein scheint.

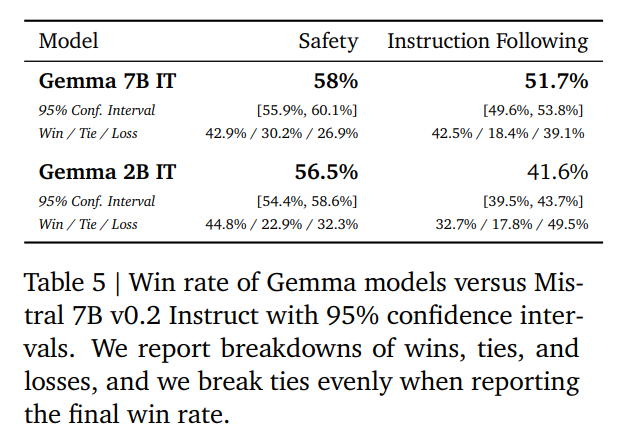
Die Fortschritte von Google sind auch insofern bemerkenswert, als mit Gemma-2B ein wesentlich kleineres Modell bei den Sicherheitstests besser abschnitt als Mistral-7B mit mehr als dreimal so vielen Parametern. Auch in Experimenten, in denen die Genauigkeit der Befolgung von Prompts bewertet wurde, lag das Modell Gemma-7B ebenfalls vorn.
Mit kommerziellen Alternativen oder auch größeren Open-Source-Modellen wie LLaMA-2-70B oder Mixtral-8x7B kann Gemma derzeit nicht konkurrieren.
Verantwortungsvolle Entwicklung steht im Vordergrund, sagt Google
"Wir sind uns bewusst, dass LLMs nicht nur Vorteile für das Ökosystem der KI-Entwicklung mit sich bringen, sondern auch in böswilliger Weise eingesetzt werden können, z. B. zur Erstellung von gefälschten Bildern, von KI-generierten Desinformationen und von illegalem und beunruhigendem Material", heißt es im Bericht.
Die Gewichte völlig frei zu veröffentlichen, anstatt das Modell hinter einer API zu verstecken, berge zusätzliches Risiko.
Deshalb habe Google verschiedene Maßnahmen ergriffen, um die Sicherheit und Zuverlässigkeit von Gemma zu gewährleisten. Persönliche Informationen und andere sensible Daten wurden aus den vortrainierten Modellen gefiltert.
Darüber hinaus wurden sie durch umfangreiches Fine-Tuning und menschliches Feedback (RLHF) an verantwortungsvolle Verhaltensweisen angepasst. Google hat die Modelle durch manuelles Red-Teaming, automatisiertes adversariales Testen und Leistungsbewertungen für gefährliche Aktivitäten nach eigenen Angaben anschließend gründlich evaluiert.
Um externen Entwickler:innen bei der Erstellung sicherer KI-Anwendungen zu helfen, hat Google außerdem das neue Responsible Generative AI Toolkit eingeführt. Dieses Toolkit enthält Sicherheitsklassifizierungsmethoden, Debugging-Tools und bewährte Verfahren, die auf Googles Erfahrungen mit großen Sprachmodellen basieren.

Gemma ist für verschiedene KI-Hardwareplattformen optimiert, darunter NVIDIA GPUs und Google Cloud TPUs. Nvidia wird die Gemma-Modelle in die eigene Daten-Chatbot-App einbinden und bietet im eigenen Playground Testversionen der Modelle Gemma 2B und Gemma 7B an.
Die Kompatibilität mit wichtigen Frameworks wie JAX, PyTorch und TensorFlow macht Gemma zu einem vielseitigen Werkzeug für eine Vielzahl von KI-Entwicklungsaufgaben.
Google erleichtert zudem den Zugang zu Gemma durch kostenlose Credits für Forschung und Entwicklung auf Plattformen wie Kaggle und Google Cloud.
Neue Cloud-Nutzer:innen erhalten ein Guthaben von 300 US-Dollar, Forschende können zudem eine Förderung in Höhe von bis zu 500.000 US-Dollar in Credits beantragen.
Google Deepmind experimentiert mit Open Source
Google hätte die Möglichkeit, Gemma durch Weiterentwicklungen auf dieses oder ein höheres Niveau zu bringen, etwa durch die Einführung multimodaler Fähigkeiten.
Gemma könnte ein Versuch von Google Deepmind sein, einen Fuß in die Tür von Open Source zu bekommen. Denn es ist bisher nicht absehbar, wie sich der Modellmarkt entwickeln wird und ob proprietäre Modelle so dominant bleiben werden, wie es derzeit bei den GPT-Modellen von OpenAI der Fall ist.
Bislang gilt Meta mit der LLaMA-Familie als Vorreiter in Sachen Big Tech Open-Source-Sprachmodelle. Im Gegensatz zu Google bietet Meta noch kein kommerzielles Sprachmodell wie Google Gemini an. Meta will mit seiner Open-Source-Politik vor allem die Entwicklerszene dominieren und an das eigene Ökosystem gewöhnen, um später effizienter hochwertigere KI-Produkte zu entwickeln.
Ein ähnliches Spiel hat Google bereits gespielt und gewonnen: das mobile Betriebssystem Android.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.