Minecraft und die ungewöhnliche Effektivität von Daten

Mit MineDojo soll die Zukunft Künstlicher Intelligenz in Minecraft entstehen: verkörperte KI-Agenten, die Welten erkunden und sich konstant selbst verbessern.
Im Sommer 2022 gründeten Wissenschaftler:innen das "Center for Research on Foundation Models (CRFM)" am Stanford Institute for Human-Centered Artificial Intelligence (HAI).
Der Begriff "Foundation Model" wurde von Forschenden aus Stanford für jedes KI-Modell vorgeschlagen, "das auf einer breiten Datenbasis trainiert wurde (im Allgemeinen unter Verwendung von Selbstüberwachung in großem Maßstab) und das an eine breite Palette nachgelagerter Aufgaben angepasst werden kann."
Ausschlaggebend waren Modelle wie OpenAIs GPT-3, die in den Monaten und Jahren nach Release ein "Paradigma für den Bau von KI-Systemen" begründeten. Wichtigste Merkmale der Foundation Modelle sei die Emergenz des Modells und seiner - teilweise unvorhergesehenen - Fähigkeiten, sowie die Homogenisierung ihrer Methoden, die in vielen Domänen abseits von Text genutzt werden.
"GPT-3 ist mächtig, aber blind"
Trotz beeindruckender Fähigkeiten haben Modelle wie GPT-3 noch immer zahlreiche Einschränkungen und sind meist auf eine Domäne beschränkt. Einige Forschende suchen daher nach Möglichkeiten, das Fundament neu zu nutzen: Methoden wie Chain-of-Thought-Prompting, Python-Zugriff, SayCan-Robotersteuerung oder die Verknüpfung mit einem Physik-Simulator sind nur einige der Ansätze, die Fähigkeiten großer Sprachmodelle erweitern.
Forschende von Nvidia, Caltech, Stanford, Columbia, der SJTU und der UT Austin sehen eine alternative Zukunft für Foundation Models: "GPT-3 ist mächtig, aber blind. Die Zukunft der Foundation Models liegt in verkörperten Agenten, die proaktiv handeln, die Welt unentwegt erkunden und sich konstant selbst verbessern", so Nvidia-Forscher Linxi Fan Twitter.
GPT3 is powerful but blind. The future of Foundation Models will be embodied agents that proactively take actions, endlessly explore the world, and continuously self-improve. What does it take? In our NeurIPS Outstanding Paper “MineDojo”, we provide a blueprint for this future:🧵 pic.twitter.com/YZps22n9pA
— Jim (Linxi) Fan (@DrJimFan) November 23, 2022
Das benötige jedoch neue Ansätze: Autonome KI-Agenten hätten in speziellen Domänen wie bei Atari- oder Go-Spielen zwar große Fortschritte erzielt. Doch sie seien nicht in der Lage, über ein breites Spektrum von Aufgaben und Fähigkeiten zu generalisieren.
Für die Emergenz generalistischer, verkörperter Agenten brauche es drei grundlegende Bedingungen, schreiben die Forschenden in einer neuen Arbeit.
Die Umgebung, in der der Agent agiert, muss eine unbegrenzte Vielfalt von Zielen mit offenem Ausgang ermöglichen.
Die natürliche Evolution werde durch die unendlich vielfältigen ökologischen Bedingungen der Erde ermöglicht. Dieser Prozess laufe seit Milliarden von Jahren unentwegt. Heutige Trainingsalgorithmen für KI-Agenten zeigten dagegen nach der Konvergenz in engen Umgebungen keine neuen Fortschritte mehr.
Eine umfangreiche Datenbank mit Vorwissen ist erforderlich, um das Lernen in offenen Umgebungen zu erleichtern.
So wie Menschen häufig aus dem Internet lernen, so sollten auch Agenten in der Lage sein, praktisches Wissen zu sammeln, schreibt das Team. Denn in einer komplexen Welt wäre es für die KI-Agenten äußerst ineffizient, von Grund auf neu per Versuch und Irrtum zu lernen. Als Quellen könnten große Mengen von Videodemos, Multimedia-Tutorials und Forumsdiskussionen dienen.
Die Architektur der Agenten muss flexibel genug sein, um jede Aufgabe in offenen Umgebungen nachgehen zu können und skalierbar genug, um die Wissensquellen in umsetzbare Erkenntnisse zu verwandeln.
Diese Bedingung motiviere den Entwurf eines Agenten, der auf natürlichsprachliche Eingaben konditioniert ist und das Transformer Vortrainings-Paradigma nutze, um Wissen aus multimodalen Quellen effektiv zu internalisieren. Eine Art "verkörpertes GPT-3".
MineDojo ist ein Trainings-Baukasten für Minecraft-KIs
Diese Ideen führt das Team mit MineDojo zusammen, einem offenen Framework zur Entwicklung von generalistischen KI-Agenten. MineDojo umfasst eine Simulator-Suite auf Grundlage von Minecraft, eine umfangreiche Internet-Datenbank und ein Grundmodell für Agenten.
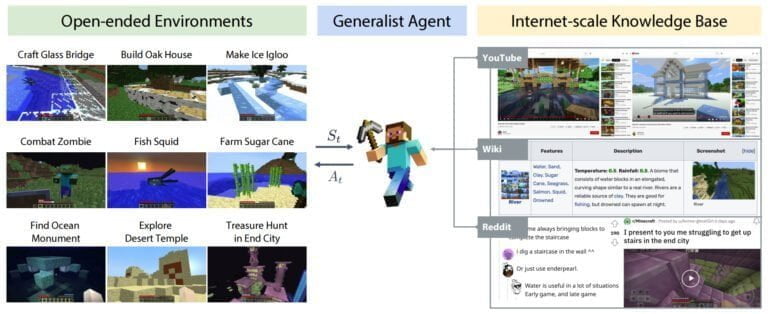
Anders als alternative Minecraft-Umgebungen für die KI-Forschung, wie etwa MineRL, unterstützt MineDojo vielseitige visuelle Inputs wie RGB, Voxel, LIDAR und GPS. Es enthält alle Welten von Minecraft (Overworld, Nether, End) und umfasst über 3.000 Aufgaben. MineDojo ist damit einer der größten Agenten-Benchmarks.
Die Aufgaben sind leicht zu evaluieren und stammen aus den Kategorien Überleben, Ernten, Tech-Tree oder Kampf, etwa "Schafe scheren, um Wolle zu gewinnen". Zudem gibt es kreative Aufgaben, die keine klar definierten oder leicht automatisierbaren Erfolgskriterien enthalten. Diese können etwa "Baue ein Spukhaus mit Zombies darin" oder "Reite ein Rennen auf einem Schwein" sein. Umgebung, Wetter und Beleuchtung lassen sich zudem detailliert anpassen.

Neben der Simulator-Suite veröffentlicht das Team eine gigantische multimodale Minecraft-Knowledge-Base: MineDojo verfügt über eine umfangreiche Sammlung von mehr als 730.000 YouTube-Videos mit zeitlich abgestimmten Transkripten, mehr als 6.000 Freiform-Wiki-Seiten und mehr als 340.000 Reddit-Beiträge mit Multimedia-Inhalten. Die Datenbank soll als Trainingsmaterial für neue KI-Agenten dienen.
MineDojo-Team stellt eigenen Minecraft-Agenten vor
Das Team stellt zudem einen eigenen KI-Agenten für Minecraft zur Verfügung. Dabei orientieren sich die Forschenden an OpenAIs CLIP und trainieren mit Minecraft-Videos von YouTube MineCLIP, ein Video-Text Modell, das natürlichsprachliche Untertitel mit zugehörigen Videosegmenten verknüpft.
Damit lernt MineCLIP etwa die Korrelation zwischen einem in Text ausgedrücktem Ziel und einem kurzen Videoschnipsel. Diese Korrelation kann in einem Wert ausgedrückt werden, den das Team als "Belohnungsfunktion für RL-Training mit offenem Vokabular und massiven Multi-Tasking-Aufgaben" verwendet. Der Agent lernt, Handlungen nach sprachlichen Aufforderungen auszuführen.
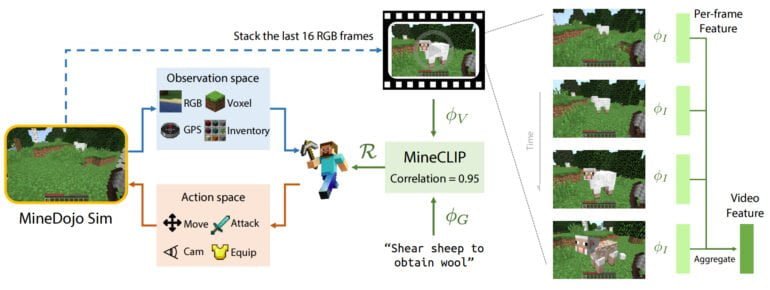
Die Qualität des vom fertig trainierten MineCLIP gelieferten Belohungssignals sei so hoch, dass die Domänenlücke zwischen verrauschtem YouTube-Video und im Simulator gerenderten Bildern nicht ins Gewicht falle. Es mache zudem die sonst übliche manuelle Entwicklung von Belohnungsfunktionen für einzelne Aufgaben im MineDojo-Benchmark überflüssig.
Besonders bei kreativen Aufgaben, bei denen es kein einfaches Erfolgskriterium gibt, erfülle MineCLIP zusätzlich eine doppelte Rolle als automatische Bewertungsmetrik, die etwa einschätzen kann, ob ein Haus mit Pool gebaut wurde und die gut mit menschlichen Bewertungen übereinstimme.
MineCLIP ist nur der Anfang
In einem Test mit zwölf Aufgaben löste der mit MineCLIP trainierte Agent die meisten dieser Aufgaben und erreicht eine konkurrenzfähige Leistung zu Agenten, die mit sorgfältig entwickelten Belohungsmodellen trainiert sind.
In einigen Aufgaben übertreffe MineCLIP andere Agenten mit einer bis zu 73 Prozent höheren Erfolgsrate, so das Team. Bei den kreativen Aufgaben mit offenem Ende schneide der Agent ebenfalls verhältnismäßig gut ab.
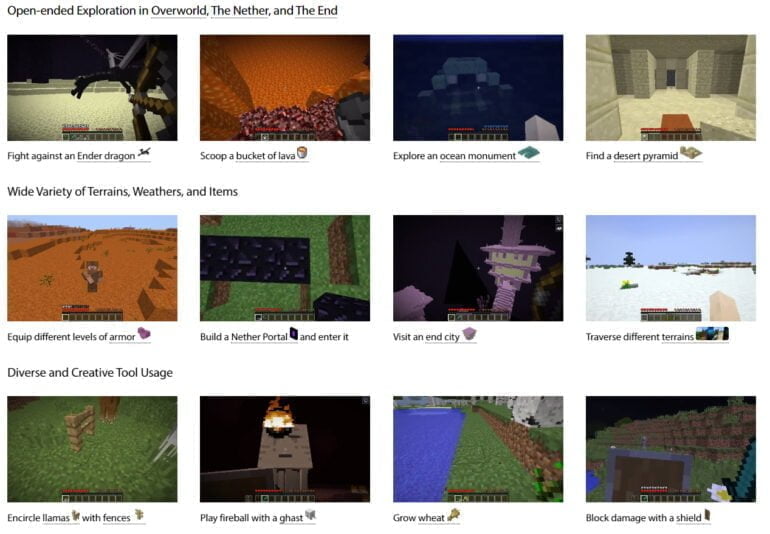
Die MineCLIP-Agenten können zudem besser mit ungesehenem Terrain, Wetter und Beleuchtung umgehen, schreiben die Forschenden. Wenn sie bereits für die zwölf Aufgaben trainiert wurden, können sie in Ansätzen auf neue Varianten dieser Aufgaben generalisieren und etwa eine neue Tierart in Minecraft jagen.
Die Forschenden betonen, dass MineCLIP nur eine von zahlreichen Möglichkeiten sei, die MineDojo-Datenbank zu nutzen. MineCLIP nutzt etwa keine der ebenfalls vorhandenen Wiki- und Reddit-Inhalte - doch auch die bergen großes Potenzial für die Entdeckung neuer Algorithmen, heißt es in der Arbeit.
Der vorgestellte Ansatz verzichte zudem auf detaillierte Anweisungen an den Agenten. Eine Idee, die etwa in SayCan genutzt wird und die das Team als potenzielle Idee für zukünftige Systeme bezeichnet.
MineCLIP und OpenAIs Video PreTraining
Laut Fan ist der gezeigte Agent ein kleiner Schritt auf dem Weg zur Vision eines "verkörperten GPT-3". MineCLIP diene als ein "Foundation Reward Model", das in jeden Algorithmus des bestärkenden Lernens eingefügt werden könne. OpenAIs Video PreTraining (VPT) sei daher ein komplementärer Ansatz und könne mit MineCLIP so angepasst werden, dass es sprachlich bedingte Aufgaben mit offenem Ende lösen kann.
VPT setzt ebenfalls auf Video-Training. Doch während MineCLIP aus Video und Text-Transkription lernt, lernte VPT aus Video und Spiel-Input: OpenAI sammelte 70.000 Stunden YouTube-Material zu Minecraft, zusätzlich weitere 2.000 Stunden Gameplay inklusive Tastatur- und Maus-Eingabedaten.
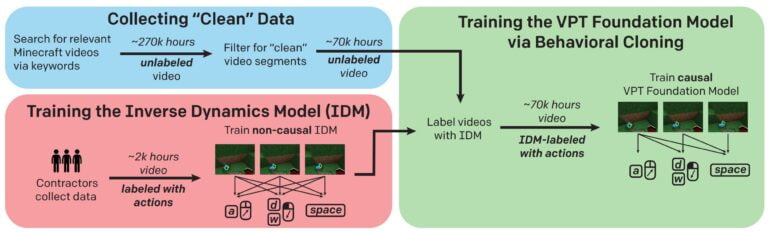
Mit den 2.000 Stunden Video trainierte OpenAI ein Inverse Dynamics Model (IDM), das anschließend die Inputs der YouTube-Videos vorhersagen konnte. So entstand ein massiver Datensatz von mehr als 70.000 Stunden Videomaterial inklusive Tastatur- und Maus-Eingabedaten für das Training des VPT-Foundational-Models.
Diese Eingabe-Daten sind wertvoll für Algorithmen, die lernen menschliches Verhalten zu imitieren und mit VPT entwickelte Methode könnte theoretisch für jede Art der Computer-Interaktion genutzt werden, für die es genügend Videos gibt. Auch OpenAI sieht jedoch die Vorteile von Text-Training: Im VPT-Paper beschreibt das Unternehmen einen Test, in dem es neben den Videos auch die Untertitel verarbeitete, da diese oft mit dem Inhalt des Videos direkt zusammenhängen - einen Fakt, den MineCLIP jetzt ausgenutzt hat.
Die ungewöhnliche Effektivität von Daten
Beide Systeme zeigen deutlich einen Trend für KI-Agenten: Ähnlich wie in der Verarbeitung natürlicher Sprache oder der Bildanalyse und -generierung entstehen durch große Datenmengen Foundation Models, die dann durch Nachtraining mit Spezialdaten mit relativ wenig Aufwand neue Aufgaben lernen können.
OpenAI trainierte etwa mit VPT einen KI-Agenten, der in zehn Minuten eine Diamant-Spitzhacke herstellt. Das liegt laut OpenAI etwa auf durchschnittlichem Mensch-Niveau.
Ob der Ansatz für die Ansprüche des MineDojo-Teams reicht, wird sich jetzt zeigen müssen. Wenn ihre Ideen stimmen, könnten uns bald verkörperte, generalisierende KI-Agenten mit einem Minecraft-Weltmodell erwarten - eine Art Probelauf für komplexere Systeme, die in unserer Welt agieren können.
Wer mehr über KI-Agenten und offene Umgebungen erfahren möchte, kann sich unseren DEEP MINDS Podcast mit Tim Rocktäschel anhören. Er ist eine der Köpfe hinter der NetHack-Challenge, die ebenfalls die Grenzen des bestärkenden Lernens verschieben soll.
Mehr Informationen über MineDojo gibt es auf der Projektseite von MineDojo. Den Code, Daten und mehr gibt es auf Github.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.